Adatáramlások figyelése
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Miután befejezte az adatfolyam összeállítását és hibakeresését, ütemeznie kell az adatfolyamot úgy, hogy a folyamat kontextusában ütemezés szerint hajtsa végre. A folyamatot eseményindítókkal ütemezheti. Az adatfolyam folyamatból való teszteléséhez és hibakereséséhez használhatja az eszköztár menüszalagjának Hibakeresés gombját, vagy a Folyamatszerkesztő Trigger Most beállítását egy egyszeri végrehajtás végrehajtásához az adatfolyam folyamatkörnyezeten belüli teszteléséhez.
A folyamat végrehajtásakor figyelheti a folyamatot és a folyamat összes tevékenységét, beleértve a Adatfolyam tevékenységet is. Válassza a figyelő ikont a bal oldali felhasználói felület panelen. A következőhöz hasonló képernyő jelenik meg. A kiemelt ikonokkal részletezheti a folyamat tevékenységeit, beleértve a Adatfolyam tevékenységet is.
A statisztikát ezen a szinten láthatja, beleértve a futtatási időket és az állapotot is. A tevékenységszinten lévő futtatási azonosító eltér a folyamat szintjén lévő futtatási azonosítótól. Az előző szintű futtatási azonosító a folyamathoz tartozik. A szemüveg kiválasztásával részletes információkat találhat az adatfolyam-végrehajtásról.

Ha grafikus csomópont figyelési nézetben van, az adatfolyam-gráf egyszerűsített, csak megtekintésre használható verzióját láthatja. Ha nagyobb, transzformációs szakaszcímkéket tartalmazó gráfcsomópontok részletes nézetét szeretné megtekinteni, használja a vászon jobb oldalán található nagyítási csúszkát. A jobb oldalon található keresés gombbal is megkeresheti az adatfolyam-logika egyes részeit a gráfban.

Adatfolyam végrehajtási tervek megtekintése
Amikor a Adatfolyam a Sparkban hajtja végre, a szolgáltatás az adatfolyam teljes egésze alapján határozza meg az optimális kódútvonalakat. Emellett a végrehajtási útvonalak különböző horizontálisan felskálázott csomópontokon és adatpartíciókon is előfordulhatnak. Ezért a monitorozási gráf a folyamat kialakítását jelöli, figyelembe véve az átalakítások végrehajtási útvonalát. Az egyes csomópontok kiválasztásakor megjelennek azok a "szakaszok", amelyek a fürtön együtt végrehajtott kódot jelölik. A látott időzítések és számok az adott csoportokat vagy szakaszokat jelölik, szemben a tervezés egyes lépéseivel.
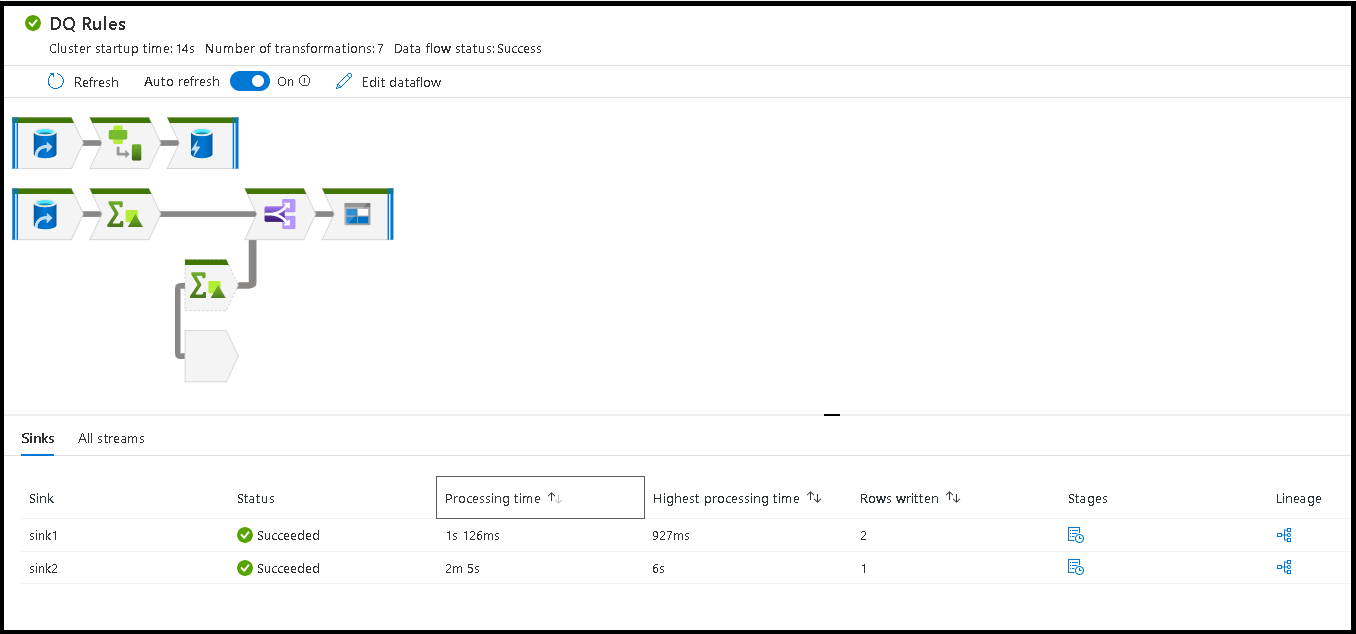
Amikor kiválasztja a nyitott területet a figyelési ablakban, az alsó panel statisztikái az időzítést és a sorok számát jelenítik meg az egyes Fogadók esetében, valamint azokat az átalakításokat, amelyek a fogadó adataihoz vezettek az átalakítási vonalhoz.
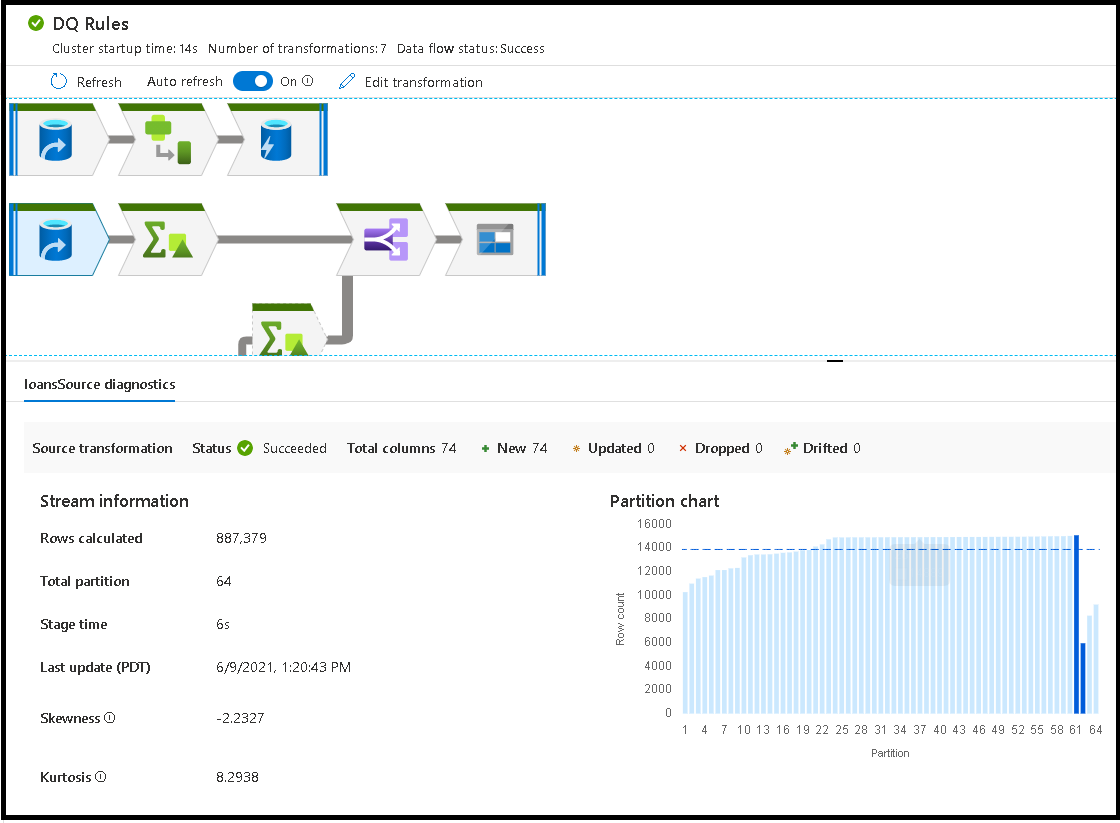
Ha egyéni átalakításokat választ ki, további visszajelzést kap a jobb oldali panelen, amely megjeleníti a partícióstatisztikákat, az oszlopszámokat, a ferdeséget (a partíciók között elosztott adatok egyenletességét) és a kurtózist (milyen tüskés az adat).
A feldolgozási idő szerinti rendezés segít megállapítani, hogy az adatfolyam mely szakaszai teltek el a legtöbb ideig.
Ha meg szeretné találni, hogy az egyes fázisokon belül mely átalakítások teltek el a legtöbb ideig, rendezze a legmagasabb feldolgozási időt.
A *megírt sorok rendezhetők is, így megállapíthatja, hogy az adatfolyamon belül mely adatfolyamok írják a legtöbb adatot.
Ha a fogadót a csomópont nézetben választja ki, láthatja az oszlopsorokat. Három különböző módszer létezik arra, hogy az oszlopok az adatfolyam során halmozódjanak fel, hogy a fogadóban landoljanak. Ezek a következők:
- Kiszámítva: Az oszlopot feltételes feldolgozáshoz vagy az adatfolyam egy kifejezéséhez használja, de ne helyezze a fogadóba
- Származtatott: Az oszlop egy új oszlop, amelyet a folyamat során létrehozott, vagyis nem volt jelen a forrásban
- Megfeleltetés: Az oszlop a forrásból származik, és egy fogadómezőre van megfeleltetve
- Adatfolyam állapota: A végrehajtás aktuális állapota
- Fürt indítási ideje: A JIT Spark számítási környezet beszerzése az adatfolyam végrehajtásához
- Átalakítások száma: Hány átalakítási lépést hajt végre a folyamat

Teljes fogadófeldolgozási idő kontra átalakításfeldolgozási idő
Az egyes átalakítási fázisok tartalmazzák az adott szakasz teljes időtartamát az összes partícióvégrehajtási idő együttvéve. Amikor kiválasztja a fogadót, megjelenik a "Fogadó feldolgozási ideje". Ez az idő magában foglalja az átalakítási idő teljes összegét és az adatok céltárolóba való írásához használt I/O-időt. A fogadó feldolgozási ideje és az átalakítás összege közötti különbség az adatok írásához szükséges I/O-idő.
Az egyes partícióátalakítási lépések részletes időzítését is megtekintheti, ha az adatfolyam-tevékenység JSON-kimenetét a folyamatfigyelési nézetben nyitja meg. A JSON az egyes partíciók ezredmásodperces időzítését tartalmazza, míg az UX monitorozási nézet a partíciók összesített időzítését tartalmazza:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Fogadó feldolgozási ideje
Amikor kiválaszt egy fogadóátalakítási ikont a térképen, a jobb oldali diapanelen megjelenik egy további adatpont, az úgynevezett "utófeldolgozási idő". Ez az az idő, amelyet a feladat végrehajtása a Spark-fürtön az adatok betöltése, átalakítása és írása után töltött. Ez az idő magában foglalhatja a kapcsolatkészletek bezárását, az illesztőprogram leállítását, a fájlok törlését, a fájlok szenesítését stb. Amikor olyan műveleteket hajt végre a folyamaton, mint a "fájlok áthelyezése" és a "kimenet egyetlen fájlba", valószínűleg megnő a feldolgozási idő utáni érték.
- Írási fázis időtartama: Az adatok synapse SQL-hez tartozó átmeneti helyre való írásának ideje
- Táblaművelet SQL-időtartama: Az adatok ideiglenes táblákból céltáblába való áthelyezésével töltött idő
- SQL-időtartam előtti és SQL-időtartam utáni időtartam: Az SQL-parancsok előtti/utáni futtatás időtartama
- Az előparancsok időtartama &a parancsok utáni időtartam: A fájlalapú forrás/fogadók elő-/utáni műveleteinek futtatásával töltött idő. Például fájlok áthelyezése vagy törlése a feldolgozás után.
- Egyesítés időtartama: A fájl egyesítésével és a fájlok egyesítésével töltött idő a fájlalapú fogadókhoz használatos, amikor egyetlen fájlba ír, vagy amikor a "Fájlnév oszlopadatokként" szöveget használja. Ha jelentős időt tölt ebben a metrikában, ne használja ezeket a beállításokat.
- Fázisidő: A Sparkon belül a művelet fázisként történő befejezéséhez szükséges teljes idő.
- Ideiglenes átmeneti stabil: Az adatfolyamok által az adatbázis adatainak szakaszolásához használt ideiglenes tábla neve.
Hibasorok
A hibasor-kezelés engedélyezése az adatfolyam-fogadóban a monitorozási kimenetben is megjelenik. Amikor a fogadót a "hiba sikeres jelentése" értékre állítja, a monitorozási kimenet a fogadó figyelési csomópontjának kiválasztásakor megjeleníti a sikeres és a sikertelen sorok számát.

Ha a "hibajelentés hibája" lehetőséget választja, ugyanaz a kimenet csak a tevékenységfigyelési kimeneti szövegben jelenik meg. Ennek az az oka, hogy az adatfolyam-tevékenység sikertelen végrehajtást ad vissza, és a részletes figyelési nézet nem érhető el.

Ikonok monitorozása
Ez az ikon azt jelenti, hogy az átalakítási adatok már gyorsítótárazva lettek a fürtön, ezért az időzítés és a végrehajtási útvonal figyelembe vette ezt:

Az átalakítás során zöld körikonok is láthatók. Ezek a fogadók száma, amelyekbe az adatok áramlanak.