ใช้ Livy API เพื่อส่งและดําเนินการชุดงาน Livy
หมายเหตุ
Livy API สําหรับ Fabric วิศวกรข้อมูล ing อยู่ในตัวอย่าง
นําไปใช้กับ:✅ วิศวกรข้อมูลและวิทยาศาสตร์ข้อมูลใน Microsoft Fabric
ส่งชุดงาน Spark โดยใช้ Livy API สําหรับ Fabric วิศวกรข้อมูล
ข้อกำหนดเบื้องต้น
ไคลเอ็นต์ระยะไกล เช่น Visual Studio Code พร้อม Jupyter Notebooks, PySpark และไลบรารีการรับรองความถูกต้องของ Microsoft (MSAL) สําหรับ Python
โทเค็นแอป Microsoft Entra จําเป็นสําหรับการเข้าถึง Fabric Rest API ลงทะเบียนแอปพลิเคชันด้วยแพลตฟอร์มข้อมูลประจำตัวของ Microsoft
ข้อมูลบางอย่างในเลคเฮ้าส์ของคุณ ตัวอย่างนี้ใช้ แท็กซี่ NYC และ Limousine Commission green_tripdata_2022_08 ไฟล์ปาร์เกตที่โหลดไปยังเลคเฮาส์
Livy API กําหนดจุดสิ้นสุดแบบรวมสําหรับการดําเนินการ แทนที่พื้นที่ที่สํารองไว้ {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} และ {Fabric_LakehouseID} ด้วยค่าที่เหมาะสมเมื่อคุณทําตามตัวอย่างในบทความนี้
กําหนดค่ารหัส Visual Studio สําหรับชุด Livy API ของคุณ
เลือก การตั้งค่า เลคเฮ้าส์ใน Fabric Lakehouse ของคุณ

นําทางไปยังส่วน จุด สิ้นสุด Livy

คัดลอกสายอักขระการเชื่อมต่อชุดงาน (กล่องสีแดงที่สองในรูปภาพ) ไปยังรหัสของคุณ
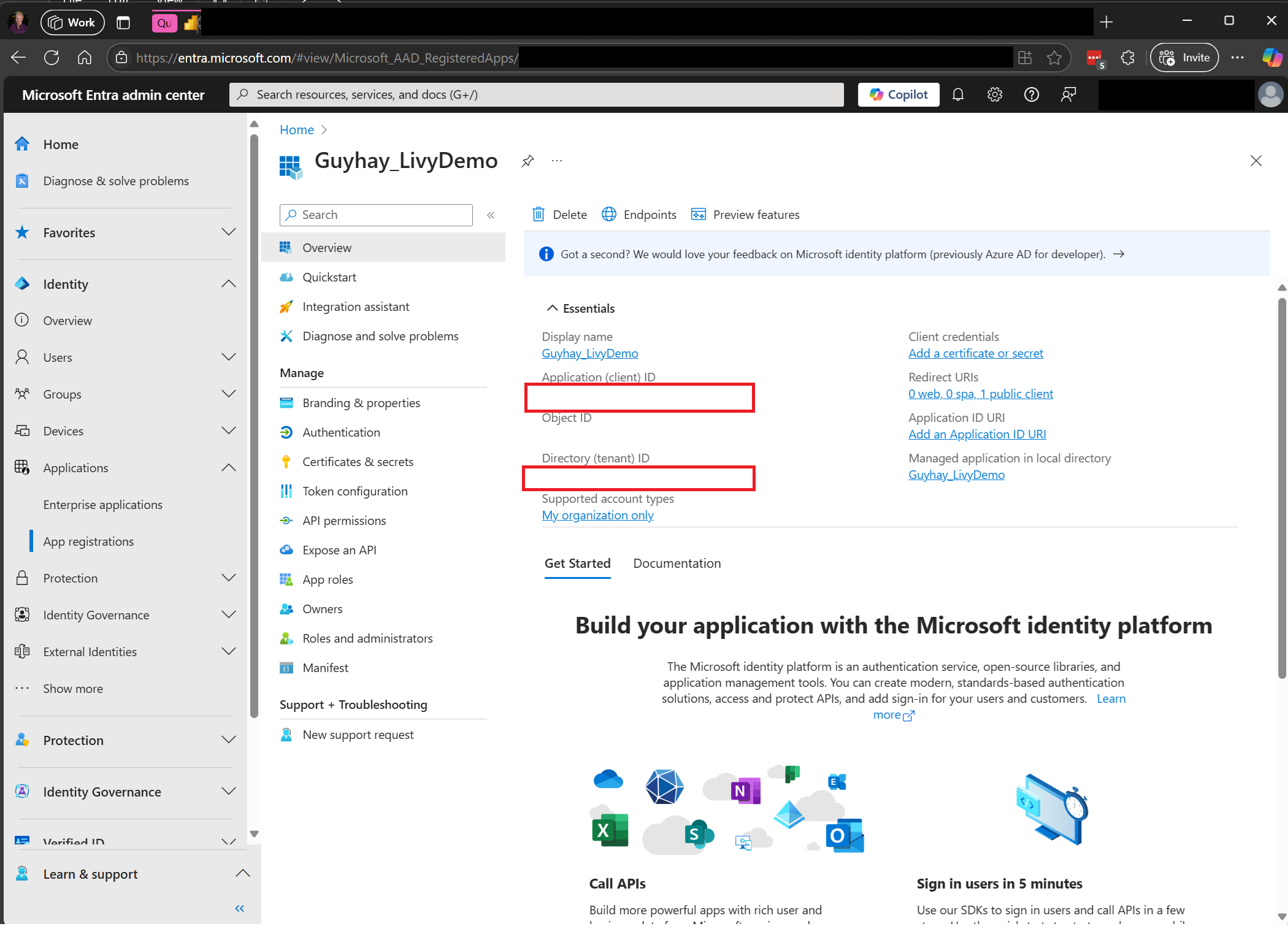
ไปที่ ศูนย์การจัดการ Microsoft Entra และคัดลอกทั้ง ID แอปพลิเคชัน (ไคลเอนต์) และ ID ไดเรกทอรี (ผู้เช่า) ไปยังรหัสของคุณ



สร้างเพย์โหลด Spark และอัปโหลดไปยัง Lakehouse ของคุณ
.ipynbสร้างสมุดบันทึกใน Visual Studio Code และแทรกโค้ดต่อไปนี้import sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)บันทึกไฟล์ Python ภายในเครื่อง ส่วนข้อมูลรหัส Python นี้ประกอบด้วยคําสั่ง Spark สองคําสั่งที่ทํางานบนข้อมูลใน Lakehouse และจําเป็นต้องอัปโหลดไปยังเลคเฮ้าส์ของคุณ คุณจะต้องมีเส้นทาง ABFS ของส่วนข้อมูลเพื่ออ้างอิงในชุดงาน Livy API ของคุณในรหัส Visual Studio Code และชื่อตาราง Lakehouse ของคุณในคําสั่ง เลือก SQL

อัปโหลดส่วนข้อมูล Python ไปยังส่วนไฟล์ของเลคเฮ้าส์ของคุณ > รับข้อมูล > อัปโหลดไฟล์ > คลิกในกล่องไฟล์/ ป้อนเข้า

หลังจากที่ไฟล์อยู่ในส่วนของไฟล์ของเลคเฮ้าส์ของคุณ คลิกที่สามจุดทางด้านขวาของชื่อไฟล์ส่วนข้อมูลของคุณ และเลือกคุณสมบัติ

คัดลอกเส้นทาง ABFS นี้ไปยังเซลล์ของสมุดบันทึกของคุณในขั้นตอนที่ 1



สร้างเซสชันชุดงาน Livy API Spark
.ipynbสร้างสมุดบันทึกใน Visual Studio Code และแทรกโค้ดต่อไปนี้from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}เรียกใช้เซลล์ของสมุดบันทึก ป็อปอัพควรปรากฏในเบราว์เซอร์ของคุณ เพื่อให้คุณสามารถเลือกข้อมูลประจําตัวที่จะลงชื่อเข้าใช้ได้

หลังจากที่คุณเลือกข้อมูลประจําตัวที่จะลงชื่อเข้าใช้แล้ว คุณจะถูกขอให้อนุมัติสิทธิ์ API การลงทะเบียนแอป Microsoft Entra

ปิดหน้าต่างเบราว์เซอร์หลังจากเสร็จสิ้นการรับรองความถูกต้อง

ใน Visual Studio Code คุณควรเห็นโทเค็น Microsoft Entra ที่ส่งกลับมา

เพิ่มเซลล์สมุดบันทึกอีกเซลล์และแทรกโค้ดนี้
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)เรียกใช้เซลล์สมุดบันทึก คุณควรเห็นบรรทัดสองบรรทัดที่พิมพ์เมื่อสร้างชุดงาน Livy แล้ว






ส่งคําสั่ง spark.sql โดยใช้เซสชันชุดงาน Livy API
เพิ่มเซลล์สมุดบันทึกอีกเซลล์และแทรกโค้ดนี้
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())เรียกใช้เซลล์ของสมุดบันทึก คุณควรเห็นบรรทัดหลายบรรทัดที่พิมพ์เมื่อสร้างและเรียกใช้งานชุด Livy

นําทางกลับไปยังเลคเฮาส์ของคุณเพื่อดูการเปลี่ยนแปลง

ดูงานของคุณในฮับการตรวจสอบ
คุณสามารถเข้าถึงฮับการตรวจสอบเพื่อดูกิจกรรม Apache Spark ต่าง ๆ ได้โดยการเลือก การตรวจสอบ ในลิงก์การนําทางด้านซ้าย
เมื่อชุดงานเสร็จสมบูรณ์ คุณสามารถดูสถานะเซสชันโดยนําทางไปยัง การตรวจสอบ

เลือกและเปิดชื่อกิจกรรมล่าสุด

ในกรณีเซสชัน Livy API นี้ คุณสามารถดูการส่งชุดก่อนหน้า ของคุณ เรียกใช้รายละเอียด เวอร์ชัน Spark และการกําหนดค่าของคุณ สังเกตสถานะหยุดที่ด้านบนขวา




ในการสรุปกระบวนการทั้งหมด คุณต้องมีไคลเอ็นต์ระยะไกล เช่น Visual Studio Code โทเค็นแอป Microsoft Entra URL จุดสิ้นสุด Livy API การรับรองความถูกต้องกับเลคเฮ้าส์ของคุณ เพย์โหลด Spark ในเลคเฮ้าส์ของคุณ และในที่สุดเซสชัน Livy API เป็นชุด