Använda den inbyggda modellen för textigenkänning i Power Automate
Den fördefinierade modellen för textigenkänning i AI Builder extraherar tryckt och handskriven text från bilder och dokument. Genom att använda den här modellen kan Power Automate du skapa arbetsflöden som automatiskt bearbetar text från skannade dokument, foton och PDF-filer, vilket möjliggör effektiv datahantering och integrering med andra program.
Det här dokumentet innehåller en guide om hur du använder den fördefinierade modellen för textigenkänning i Power Automate.
Initiera Power Automate-flödet
Att initiera Power Automate flödet är det första steget i att konfigurera den automatiserade processen. I det här steget kan du definiera utlösaren och de inledande indataparametrarna för ditt flöde. När du initierar kan du se till att flödet startar korrekt och har den information som krävs för att bearbeta textigenkänningsuppgifterna effektivt.
Gör så här om du vill initiera ditt flöde:
Logga in på Power Automate.
I den vänstra menyn väljer du Mina flöden och välj sedan Nytt flöde>Direkt molnflöde.
Namnge ditt flöde, välj Utlös flödet manuellt under Välj hur du vill utlösa det här flödet och välj sedan Skapa.
Visa Utlös flödet manuellt, välj +Lägg till indata>Fil som indatatyp.
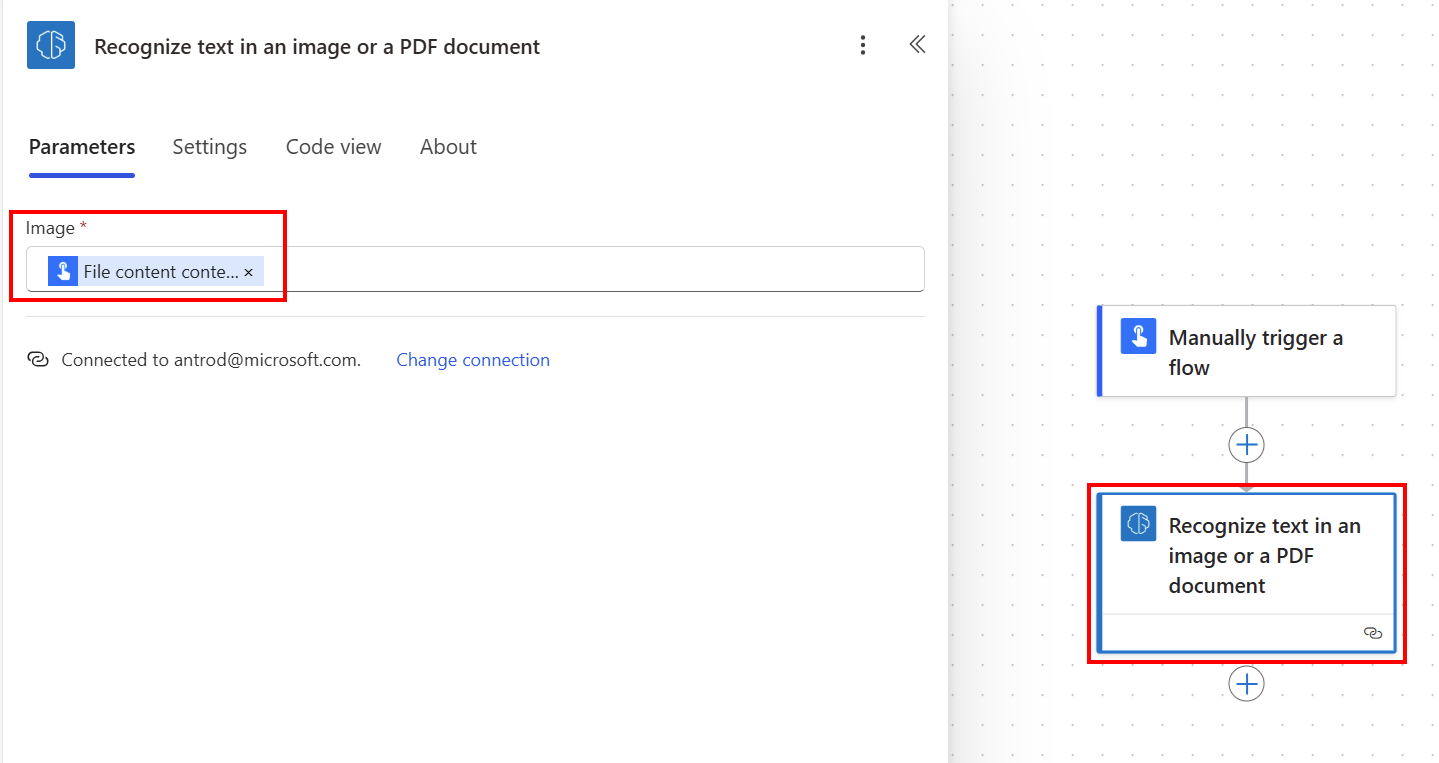
Välj +Nytt steg>AI Builder och välj sedan Känna igen text i en bild eller ett PDF-dokument i listan över åtgärder.
Markera Bild inmatning och välj Filinnehåll i listan Dynamiskt innehåll:
Om du vill bearbeta resultat kan du antingen använda den fullständiga dokumenttexten, en sidtext eller dokumenttexten rad för rad.
Hämta hela dokumenttexten eller en hel sidestext
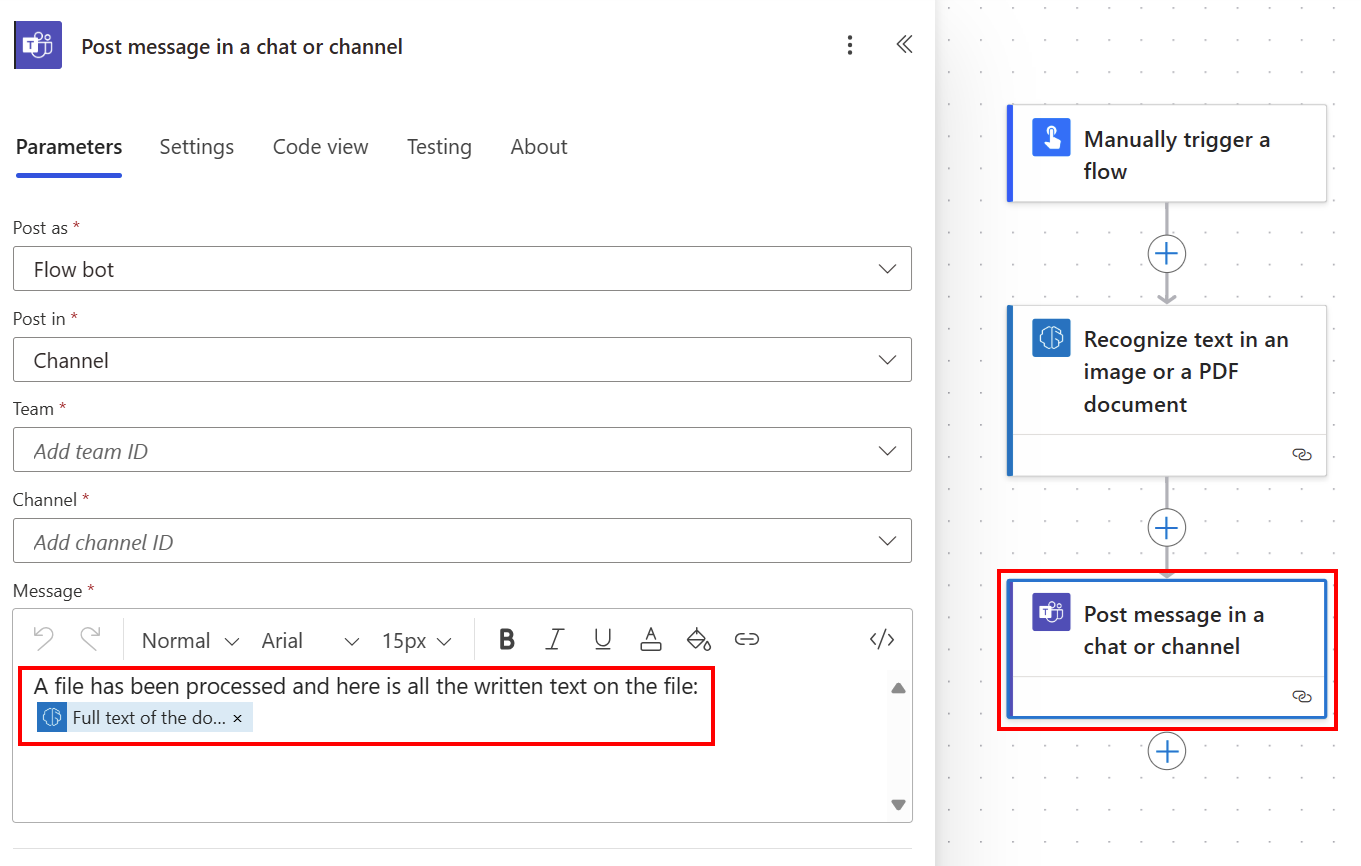
Om du behöver utföra en åtgärd på hela dokumenttexten eller på en viss sidtext är det här alternativet användbart. Ett exempel på hur du använder sidtext är när du vill söka efter en delsträng eller skicka den till en underordnad åtgärd.
Du kan publicera all extraherad text i en Teams-kanal med hjälp av fulltext i dokumentet från listan Dynamiskt innehåll.
Få dokumentets text rad för rad
Att få dokumentet text rad för rad kan vara användbart om du behöver isolera en viss textrad eller formatera om texten när det passar dig.
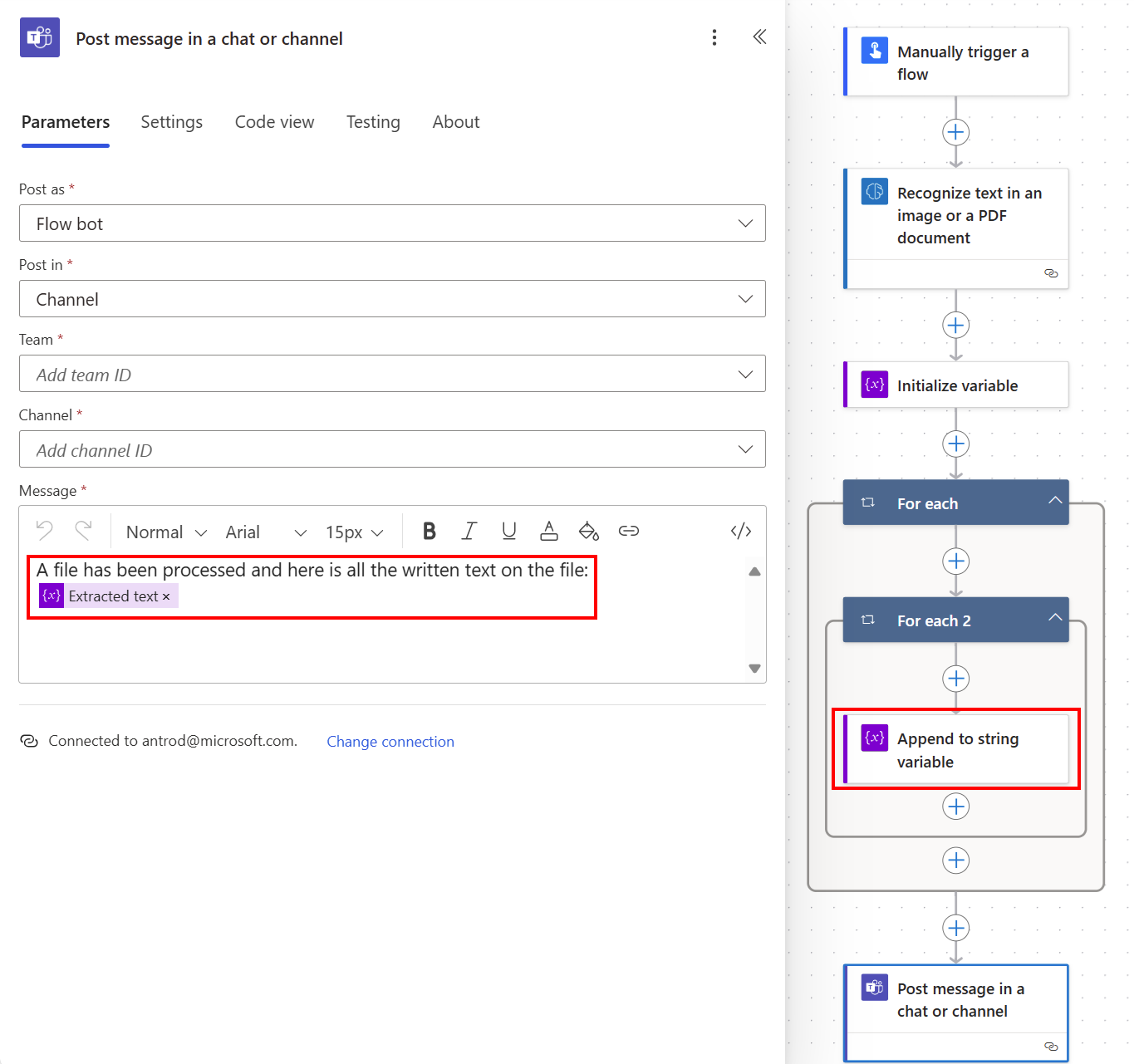
Om du vill skapa en strängvariabel väljer du +Nytt steg>Kontroll och väljer sedan Initiera variabel.
Ge den namnet Extraherad text till exempel.
Välj +Nytt steg>Kontroll och väljer sedan Lägga till strängvariabel.
I fältet värde välj Text från listan Dynamiskt innehåll.
Den genererar automatiskt två åtgärder för Tillämpa för varje när den läser en lista med radtext i en lista med sidor. Du kan sedan publicera all extraherad text i en Teams-kanal.
Klar! Du har skapat ett flöde som använder en textidentifieringsmodell. Du kan fortsätta att utveckla flödet så att det överensstämmer med dina behov. Välj Spara högst upp till höger och välj sedan Testa för att testa ditt flöde.
Parametrar
Den fördefinierade modellen för textigenkänning i AI Builder innehåller följande indata- och utdataparametrar.
Indata
| Name | Obligatoriskt | Type | Description |
|---|---|---|---|
| Bild | Ja | file | Bild som ska analyseras |
Utdata
Den identifierade texten är inbäddad i rader underlista i resultat listan. Du måste först markera kolumnen rader från åtgärden Tillämpa för varje för att visa alla följande kolumner.
| Namn | Typ | Beskrivning |
|---|---|---|
| Text | sträng | Strängar som innehåller textraden som identifierades |
| Sidnummer | sträng | Sidnummer för den text som identifieras |
| Koordinater | flyttal | Koordinater för den text som identifieras |
| Dokumentets hela text | string | Fullständig text identifieras |
| Sidans hela text | string | Fullständig sidtext identifieras |