Čo je sémantické prepojenie?
Sémantické prepojenie je funkcia, ktorá umožňuje vytvoriť spojenie medzi sémantickými modelmi a službou Synapse Data Science v službe Microsoft Fabric. Použitie sémantických prepojení je podporované iba v službe Microsoft Fabric.
Pre službu Spark 3.4 a vyššiu je sémantické prepojenie dostupné v predvolenom režime runtime pri použití služby Fabric a nie je potrebné ju nainštalovať.
Pre službu Spark 3.3 alebo novšiu alebo aktualizáciu na najnovšiu verziu sémantického prepojenia spustite nasledujúci príkaz:
%pip install -U semantic-link
Hlavné ciele sémantického prepojenia sú:
- uľahčiť pripojenie k údajom,
- Povoľte šírenie sémantických informácií.
- Bezproblémová integrácia s vytvorenými nástrojmi, ktoré používajú dátoví vedci, ako sú napríklad poznámkové bloky.
Sémantické prepojenie pomáha zachovať znalosti domény o sémantike údajov štandardizovaným spôsobom, ktorý môže urýchliť analýzu údajov a znížiť chyby.
Tok údajov sémantickým prepojením
Tok údajov sémantického prepojenia začína so sémantickými modelmi, ktoré obsahujú údaje a sémantické informácie. Sémantické prepojenie prekoná priepasť medzi Power BI a skúsenosťami služby Synapse Data Science.
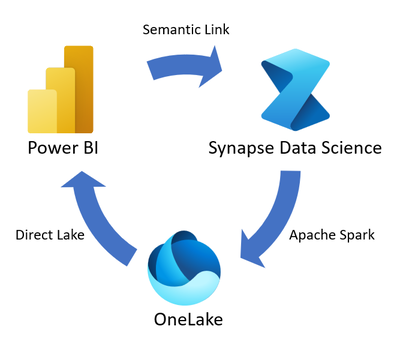
Sémantické prepojenie vám umožňuje používať sémantické modely zo služby Power BI v prostredí Synapse Data Science na vykonávanie úloh, ako je napríklad hĺbková štatistická analýza a prediktívne modelovanie s technikami strojového učenia. Výstup vašej dátovej vedy môžete uložiť do OneLakeu pomocou Apache Spark a uložený výstup do služby Power BI ingestovať pomocou Direct Lake.
Pripojenie k službe Power BI
Sémantický model slúži ako jeden tabuľkový objektový model , ktorý poskytuje spoľahlivé zdroje pre sémantické definície, ako sú napríklad mierky Power BI. Sémantické prepojenie sa pripája k sémantickým modelom v nasledujúcich ekosystémoch, vďaka čomu dátoví vedci môžu jednoduchšie pracovať v systéme, ktorý najviac poznajú.
- Ekosystém Pandas jazyka Python prostredníctvom knižnice SemPy Python.
- Ekosystém Apache Spark prostredníctvom natívneho konektora Spark. Táto implementácia podporuje rôzne jazyky vrátane PySparku, Spark SQL, R a Scala.
Aplikácie sémantických informácií
Sémantické informácie v údajoch zahŕňajú kategórie údajov služby Power BI, ako sú adresa a PSČ, vzťahy medzi tabuľkami a hierarchické informácie.
Tieto kategórie údajov zahŕňajú metaúdaje, ktoré sa sémantické prepojenie šíri do prostredia Synapse Data Science, aby bolo možné vytvárať nové skúsenosti a udržiavať pôvod údajov.
Niektoré príklady aplikácií sémantických prepojení zahŕňajú:
- Inteligentné návrhy vstavaných sémantických funkcií.
- Inovatívna integrácia na rozšírenie údajov pomocou mierok Power BI pomocou doplnkov.
- Nástroje na overenie kvality údajov na základe vzťahov medzi tabuľkami a funkčných závislostí v tabuľkách.
Sémantické prepojenie je výkonný nástroj, ktorý podnikovým analytikom umožňuje efektívne používať údaje v komplexnom prostredí dátovej vedy.
Sémantické prepojenie uľahčuje bezproblémovú spoluprácu medzi dátovými vedcami a obchodnými analytikmi tým, že eliminuje potrebu opätovného prepojenia obchodnej logiky zahrnutej v mierkach služby Power BI. Tento prístup zaručuje, že obe strany môžu pracovať efektívne a produktívne a maximalizovať potenciál svojich prehľadov založených na údajoch.
Štruktúra údajov fabricDataFrame
FabricDataFrame je primárna štruktúra údajov, ktorá sémantické prepojenie používa na šírenie sémantických informácií zo sémantických modelov do prostredia Synapse Data Science.

Trieda FabricDataFrame :
- Podporuje všetky operácie pandas.
- Podtriedy pandas DataFrame a pridáva metaúdaje, ako sú sémantické informácie a pôvod.
- Sprístupňuje sémantické funkcie a metódu pridania mierky , ktorá vám umožňuje používať mierky Power BI v práci dátovej vedy.
Súvisiaci obsah
- Preskúmajte referenčnú dokumentáciu pre balík sémantických prepojení v jazyku Python (SemPy)
- Kurz: Vyčistenie údajov pomocou funkčných závislostí
- Pripojenie k službe Power BI so sémantickým prepojením a službou Microsoft Fabric
- Preskúmanie a overenie údajov pomocou sémantického prepojenia
- Preskúmanie a overenie vzťahov v sémantických modeloch