Použitie tidyverse
Tidyverse je kolekcia balíkov R, ktoré dátoví vedci bežne používajú v každodenných analýzach údajov. Obsahuje balíky na import údajov (readr), vizualizáciu údajov (ggplot2), manipuláciu s údajmi (dplyr, tidyr), funkčné programovanie (purrr) a vytváranie modelov (tidymodels) atď. Balíky v tidyverse sú navrhnuté tak, aby bezproblémovo spolupracovali a dodržiavali jednotný súbor zásad návrhu.
Microsoft Fabric distribuuje najnovšiu stabilnú verziu aplikácie s každým vydaním modulu tidyverse runtime. Importujte a začnite používať svoje známe balíky R.
Požiadavky
Získajte predplatné na Microsoft Fabric. Alebo si zaregistrujte bezplatnú skúšobnú verziu služby Microsoft Fabric.
Prihláste sa do služby Microsoft Fabric.
Pomocou prepínača skúseností v ľavej dolnej časti domovskej stránky sa prepnete na službu Fabric.

Otvorte alebo vytvorte poznámkový blok. Ďalšie informácie nájdete v téme Ako používať poznámkové bloky služby Microsoft Fabric.
Ak chcete zmeniť primárny jazyk, nastavte možnosť jazyka na SparkR (R ).
Pripojte svoj notebook k jazeru. Na ľavej strane vyberte položku Pridať a pridajte existujúci lakehouse alebo vytvorte lakehouse.
Naložiť tidyverse
# load tidyverse
library(tidyverse)
Import údajov
readr je balík R, ktorý poskytuje nástroje na čítanie obdĺžnikových údajových súborov, ako sú napríklad SÚBORY CSV, TSV a súbory s pevnou šírkou.
readr Poskytuje rýchly a priateľský spôsob čítania obdĺžnikových údajových súborov, napríklad poskytuje funkcie read_csv() a read_tsv() na čítanie CSV súborov a súborov TSV.
Najprv vytvoríme súbor r data.frame, napíšme ho do lakehouse pomocou readr::write_csv() a načítajme ho späť pomocou readr::read_csv().
Poznámka
Ak chcete získať prístup k súborom Lakehouse pomocou readr, musíte použiť cestu k súboru API. V prieskumníkovi Lakehouse kliknite pravým tlačidlom myši na súbor alebo priečinok, ku ktorému chcete získať prístup, a skopírujte jeho cestu k súboru API z kontextovej ponuky.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Potom údaje napíšeme do útla Lakehouse pomocou cesty rozhrania API súboru.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Prečítajte si údaje z lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Upratanie údajov
tidyr je balík R, ktorý poskytuje nástroje na prácu s chaotickými údajmi. Hlavné funkcie funkcie sú tidyr navrhnuté tak, aby vám pomohli pretvoriť údaje do úhľadného formátu. Upratané údaje majú špecifickú štruktúru, kde každá premenná je stĺpec a každé pozorovanie je riadok, čo uľahčuje prácu s údajmi v R a ďalších nástrojoch.
Funkciu in gather() možno napríklad použiť na konverziu tidyr širokých údajov na dlhé údaje. Príklad:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funkčné programovanie
purrr je balík R, ktorý zlepšuje súpravu nástrojov funkčného programovania jazyka R tým, že poskytuje úplnú a konzistentnú sadu nástrojov na prácu s funkciami a vektormi. Najlepšie miesto, kde začať, purrr je skupina funkcií map() , ktoré vám umožnia nahradiť veľa pre slučky s kódom, ktorý je ako stručnejšie a ľahšie čitateľné. Tu je príklad použitia map() funkcie na každý prvok zoznamu:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulácia s údajmi
dplyr je balík R, ktorý poskytuje konzistentnú množinu slovies, ktoré vám pomôžu vyriešiť najčastejšie problémy s manipuláciou s údajmi, ako napríklad výber premenných na základe názvov, výber prípadov na základe hodnôt, zníženie viacerých hodnôt až na jeden súhrn a zmena poradia riadkov atď. Tu je niekoľko príkladov:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Vizualizácia údajov
ggplot2 je balík R na deklaratívne vytváranie grafických prvkov na základe gramatiky grafiky. Môžete zadať údaje, zistiť ggplot2 , ako mapovať premenné k estetike, aké grafické primitívnosti použiť, a to sa stará o podrobnosti. Tu sú niektoré príklady:
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()

# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()

Vytváranie modelov
Rámec tidymodels je kolekcia balíkov na modelovanie a strojové učenie pomocou tidyverse zásad. Zahŕňa zoznam základných balíkov pre širokú škálu úloh vytvárania modelov, ako rsample je napríklad rozdelenie parsnip ukážky trénovania/testovania množiny údajov, podľa špecifikácie modelu, recipes pre predprocesovanie údajov, workflows na modelovanie pracovných postupov, tune ladenie hyperparametrov, yardstick vyhodnocovanie modelu, broom na tidovanie výstupov modelov a dials na spravovanie parametrov ladenia. Ďalšie informácie o balíkoch nájdete na webovej lokalite služby tidymodels. Tu je príklad vytvorenia lineárneho regresného modelu na predpovedanie míľ na galón (mpg) vozidla na základe jeho hmotnosti (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
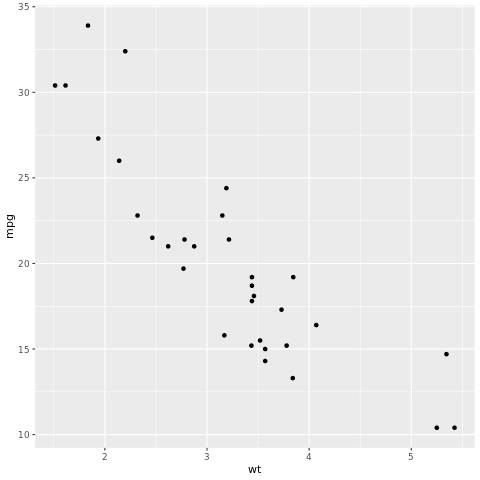
V bodovom grafe vyzerá vzťah približne lineárne a odchýlka vyzerá konštantne. Skúsme to modelovať pomocou lineárnej regresie.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Použite lineárny regresný model na predpovedanie na testovacej množine údajov.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
Pozrime sa na výsledok modelu. Môžeme nakresliť model ako čiarový graf a údaje o pravdivosti testovacej pôdy ako body v tom istom grafe. Model vyzerá dobre.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")
