Tutorial: Evaluate a model's response with response caching and reporting
In this tutorial, you create an MSTest app to evaluate the chat response of an OpenAI model. The test app uses the Microsoft.Extensions.AI.Evaluation libraries to perform the evaluations, cache the model responses, and create reports. The tutorial uses both a built-in evaluator and a custom evaluator.
Prerequisites
- .NET 8 or a later version
- Visual Studio Code (optional)
Configure the AI service
To provision an Azure OpenAI service and model using the Azure portal, complete the steps in the Create and deploy an Azure OpenAI Service resource article. In the "Deploy a model" step, select the gpt-4o model.
Create the test app
Complete the following steps to create an MSTest project that connects to the gpt-4o AI model.
In a terminal window, navigate to the directory where you want to create your app, and create a new MSTest app with the
dotnet newcommand:dotnet new mstest -o TestAIWithReportingNavigate to the
TestAIWithReportingdirectory, and add the necessary packages to your app:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions --prerelease dotnet add package Microsoft.Extensions.AI.Evaluation --prerelease dotnet add package Microsoft.Extensions.AI.Evaluation.Quality --prerelease dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting --prerelease dotnet add package Microsoft.Extensions.AI.OpenAI --prerelease dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsRun the following commands to add app secrets for your Azure OpenAI endpoint, model name, and tenant ID:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-azure-openai-endpoint> dotnet user-secrets set AZURE_OPENAI_GPT_NAME gpt-4o dotnet user-secrets set AZURE_TENANT_ID <your-tenant-id>(Depending on your environment, the tenant ID might not be needed. In that case, remove it from the code that instantiates the DefaultAzureCredential.)
Open the new app in your editor of choice.
Add the test app code
Rename the Test1.cs file to MyTests.cs, and then open the file and rename the class to
MyTests. Delete the emptyTestMethod1method.Add the necessary
usingdirectives to the top of the file.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;Add the TestContext property to the class.
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Add the
GetAzureOpenAIChatConfigurationmethod, which creates the IChatClient that the evaluator uses to communicate with the model.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string model = config["AZURE_OPENAI_GPT_NAME"]; string tenantId = config["AZURE_TENANT_ID"]; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.AsChatClient(modelId: model); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Set up the reporting functionality.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Scenario name
The scenario name is set to the fully qualified name of the current test method. However, you can set it to any string of your choice when you call CreateScenarioRunAsync(String, String, IEnumerable<String>, CancellationToken). Here are some considerations for choosing a scenario name:
- When using disk-based storage, the scenario name is used as the name of the folder under which the corresponding evaluation results are stored. So it's a good idea to keep the name reasonably short and avoid any characters that aren't allowed in file and directory names.
- By default, the generated evaluation report splits scenario names on
.so that the results can be displayed in a hierarchical view with appropriate grouping, nesting, and aggregation. This is especially useful in cases where the scenario name is set to the fully qualified name of the corresponding test method, since it allows the results to be grouped by namespaces and class names in the hierarchy. However, you can also take advantage of this feature by including periods (.) in your own custom scenario names to create a reporting hierarchy that works best for your scenarios.
Execution name
The execution name is used to group evaluation results that are part of the same evaluation run (or test run) when the evaluation results are stored. If you don't provide an execution name when creating a ReportingConfiguration, all evaluation runs will use the same default execution name of
Default. In this case, results from one run will be overwritten by the next and you lose the ability to compare results across different runs.This example uses a timestamp as the execution name. If you have more than one test in your project, ensure that results are grouped correctly by using the same execution name in all reporting configurations used across the tests.
In a more real-world scenario, you might also want to share the same execution name across evaluation tests that live in multiple different assemblies and that are executed in different test processes. In such cases, you could use a script to update an environment variable with an appropriate execution name (such as the current build number assigned by your CI/CD system) before running the tests. Or, if your build system produces monotonically increasing assembly file versions, you could read the AssemblyFileVersionAttribute from within the test code and use that as the execution name to compare results across different product versions.
Reporting configuration
A ReportingConfiguration identifies:
- The set of evaluators that should be invoked for each ScenarioRun that's created by calling CreateScenarioRunAsync(String, String, IEnumerable<String>, CancellationToken).
- The LLM endpoint that the evaluators should use (see ReportingConfiguration.ChatConfiguration).
- How and where the results for the scenario runs should be stored.
- How LLM responses related to the scenario runs should be cached.
- The execution name that should be used when reporting results for the scenario runs.
This test uses a disk-based reporting configuration.
In a separate file, add the
WordCountEvaluatorclass, which is a custom evaluator that implements IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }The
WordCountEvaluatorcounts the number of words present in the response. Unlike some evaluators, it isn't based on AI. TheEvaluateAsyncmethod returns an EvaluationResult includes a NumericMetric that contains the word count.The
EvaluateAsyncmethod also attaches a default interpretation to the metric. The default interpretation considers the metric to be good (acceptable) if the detected word count is between 6 and 100. Otherwise, the metric is considered failed. This default interpretation can be overridden by the caller, if needed.Back in
MyTests.cs, add a method to gather the evaluators to use in the evaluation.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator rtcEvaluator = new RelevanceTruthAndCompletenessEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [rtcEvaluator, wordCountEvaluator]; }Add a method to add a system prompt ChatMessage, define the chat options, and ask the model for a response to a given question.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }The test in this tutorial evaluates the LLM's response to an astronomy question. Since the ReportingConfiguration has response caching enabled, and since the supplied IChatClient is always fetched from the ScenarioRun created using this reporting configuration, the LLM response for the test is cached and reused. The response will be reused until the corresponding cache entry expires (in 14 days by default), or until any request parameter, such as the the LLM endpoint or the question being asked, is changed.
Add a method to validate the response.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceTruthAndCompletenessEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for truth from the <see cref="EvaluationResult"/>. NumericMetric truth = result.Get<NumericMetric>(RelevanceTruthAndCompletenessEvaluator.TruthMetricName); Assert.IsFalse(truth.Interpretation!.Failed, truth.Reason); Assert.IsTrue(truth.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for completeness from the <see cref="EvaluationResult"/>. NumericMetric completeness = result.Get<NumericMetric>(RelevanceTruthAndCompletenessEvaluator.CompletenessMetricName); Assert.IsFalse(completeness.Interpretation!.Failed, completeness.Reason); Assert.IsTrue(completeness.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Tip
The metrics each include a
Reasonproperty that explains the reasoning for the score. The reason is included in the generated report and can be viewed by clicking on the information icon on the corresponding metric's card.Finally, add the test method itself.
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync(this.ScenarioName); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }This test method:
Creates the ScenarioRun. The use of
await usingensures that theScenarioRunis correctly disposed and that the results of this evaluation are correctly persisted to the result store.Gets the LLM's response to a specific astronomy question. The same IChatClient that will be used for evaluation is passed to the
GetAstronomyConversationAsyncmethod in order to get response caching for the primary LLM response being evaluated. (In addition, this enables response caching for the LLM turns that the evaluators use to perform their evaluations internally.) With response caching, the LLM response is fetched either:- Directly from the LLM endpoint in the first run of the current test, or in subsequent runs if the cached entry has expired (14 days, by default).
- From the (disk-based) response cache that was configured in
s_defaultReportingConfigurationin subsequent runs of the test.
Runs the evaluators against the response. Like the LLM response, on subsequent runs, the evaluation is fetched from the (disk-based) response cache that was configured in
s_defaultReportingConfiguration.Runs some basic validation on the evaluation result.
This step is optional and mainly for demonstration purposes. In real-world evaluations, you might not want to validate individual results since the LLM responses and evaluation scores can change over time as your product (and the models used) evolve. You might not want individual evaluation tests to "fail" and block builds in your CI/CD pipelines when this happens. Instead, it might be better to rely on the generated report and track the overall trends for evaluation scores across different scenarios over time (and only fail individual builds when there's a significant drop in evaluation scores across multiple different tests). That said, there is some nuance here and the choice of whether to validate individual results or not can vary depending on the specific use case.
When the method returns, the
scenarioRunobject is disposed and the evaluation result for the evaluation is stored to the (disk-based) result store that's configured ins_defaultReportingConfiguration.
Run the test/evaluation
Run the test using your preferred test workflow, for example, by using the CLI command dotnet test or through Test Explorer.
Generate a report
Install the Microsoft.Extensions.AI.Evaluation.Console .NET tool by running the following command from a terminal window (update the version as necessary):
dotnet tool install --local Microsoft.Extensions.AI.Evaluation.Console --version 9.3.0-preview.1.25164.6Generate a report by running the following command:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlOpen the
report.htmlfile. It should look something like this.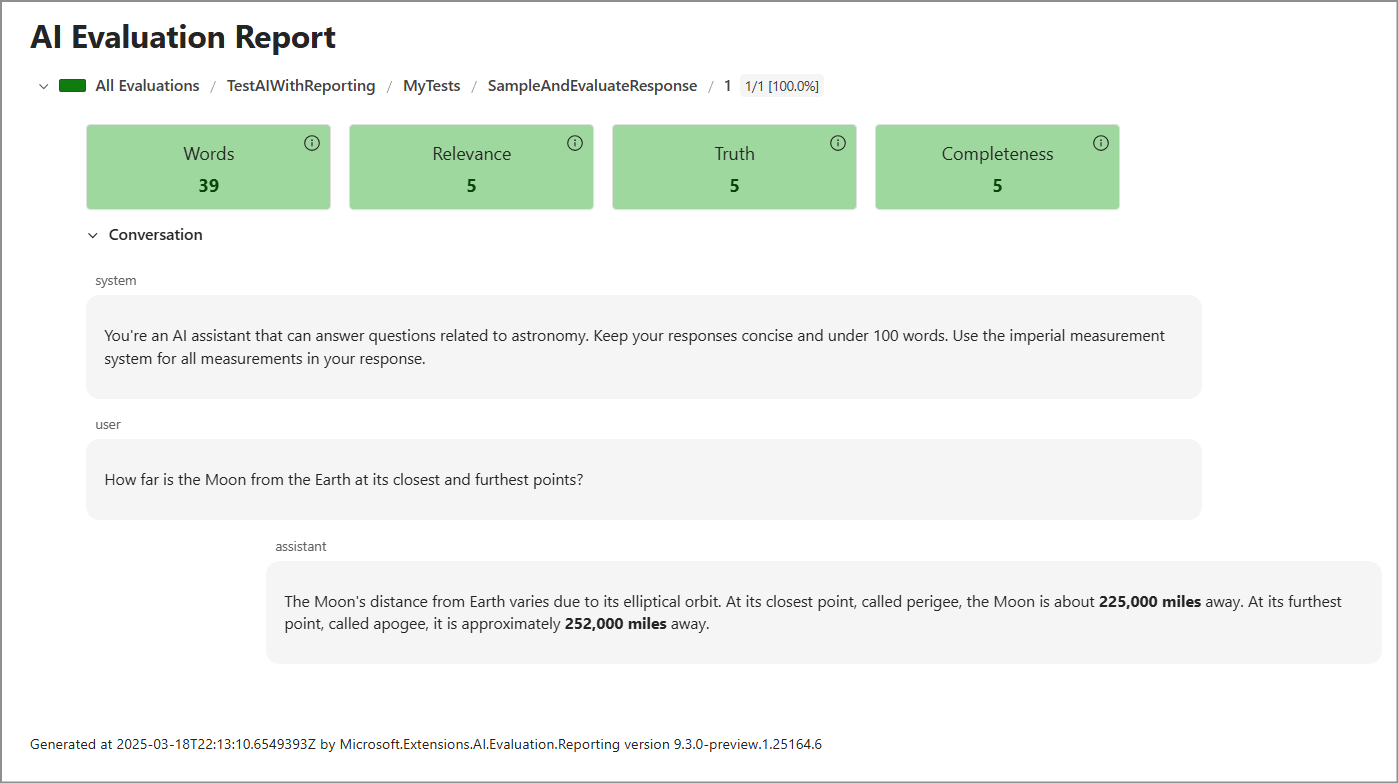
Next steps
- Navigate to the directory where the test results are stored (which is
C:\TestReports, unless you modified the location when you created the ReportingConfiguration). In theresultssubdirectory, notice that there's a folder for each test run named with a timestamp (ExecutionName). Inside each of those folders is a folder for each scenario name—in this case, just the single test method in the project. That folder contains a JSON file with the all the data including the messages, response, and evaluation result. - Expand the evaluation. Here are a couple ideas:
- Add an additional custom evaluator, such as an evaluator that uses AI to determine the measurement system that's used in the response.
- Add another test method, for example, a method that evaluates multiple responses from the LLM. Since each response can be different, it's good to sample and evaluate at least a few responses to a question. In this case, you specify an iteration name each time you call CreateScenarioRunAsync(String, String, IEnumerable<String>, CancellationToken).