예측 코딩 모델 학습(미리 보기)
중요
이 문서는 클래식 eDiscovery 환경에만 적용됩니다. 클래식 eDiscovery 환경은 2025년 8월에 사용 중지되며 사용 중지 후 Microsoft Purview 포털에서 환경 옵션으로 사용할 수 없습니다.
이 전환에 대한 계획을 일찍 시작하고 Microsoft Purview 포털에서 새 eDiscovery 환경을 사용하는 것이 좋습니다. 최신 eDiscovery 기능 및 기능을 사용하는 방법에 대한 자세한 내용은 eDiscovery에 대해 알아보기를 참조하세요.
중요
예측 코딩은 2024년 3월 31일부터 사용 중지되었으며 새로운 eDiscovery 사례에서는 사용할 수 없습니다. 학습된 예측 코딩 모델이 있는 기존 사례의 경우 기존 점수 필터를 검토 집합에 계속 적용할 수 있습니다. 그러나 새 모델을 만들거나 학습시킬 수는 없습니다.
Microsoft Purview eDiscovery(프리미엄)에서 예측 코딩 모델을 만든 후 다음 단계는 첫 번째 학습 라운드를 수행하여 검토 집합의 관련 콘텐츠와 관련이 없는 콘텐츠에 대해 모델을 학습시키는 것입니다. 첫 번째 학습을 완료한 후 후속 학습 라운드를 수행하여 관련 콘텐츠와 관련이 없는 콘텐츠를 예측하는 모델의 기능을 향상시킬 수 있습니다.
예측 코딩 워크플로를 검토하려면 eDiscovery의 예측 코딩에 대한 자세한 정보(프리미엄)를 참조하세요.
팁
E5 고객이 아닌 경우 90일 Microsoft Purview 솔루션 평가판을 사용하여 조직이 데이터 보안 및 규정 준수 요구 사항을 관리하는 데 도움이 되는 추가 Purview 기능을 살펴보세요. Microsoft Purview 평가판 허브에서 지금 시작합니다. 등록 및 평가판 조건에 대한 세부 정보를 알아봅니다.
모델을 학습하기 전에
- 학습 라운드 중에 문서에 있는 콘텐츠의 관련성에 따라 관련 항목 또는관련 없음 으로 레이블을 지정합니다. 메타데이터 필드의 값에 대한 결정을 기반으로 하지 마세요. 예를 들어 전자 메일 메시지 또는 Teams 대화의 경우 메시지 참가자에 대한 레이블 지정 결정을 기반으로 하지 않습니다.
처음으로 모델 학습
참고
제한된 시간 동안 클래식 eDiscovery 환경은 새 Microsoft Purview 포털에서 사용할 수 있습니다. eDiscovery 환경 설정에서 Purview 포털 클래식 eDiscovery 환경을 사용하도록 설정하여 새 Microsoft Purview 포털에서 클래식 환경을 표시합니다.
Microsoft Purview 포털에서 eDiscovery(프리미엄) 사례를 연 다음 , 검토 집합 탭을 선택합니다.
검토 집합을 연 다음 분석>예측 코딩 관리(미리 보기)를 선택합니다.
예측 코딩 모델(미리 보기) 페이지에서 학습할 모델을 선택합니다.
개요 탭의 1라운드 아래에서 다음 학습 라운드 시작을 선택합니다.
학습 탭이 표시되고 레이블을 지정할 50개의 항목이 포함되어 있습니다.
각 문서를 검토한 다음 읽기 창 아래쪽에서 관련성 또는 관련성 없음 을 선택하여 레이블을 지정합니다.
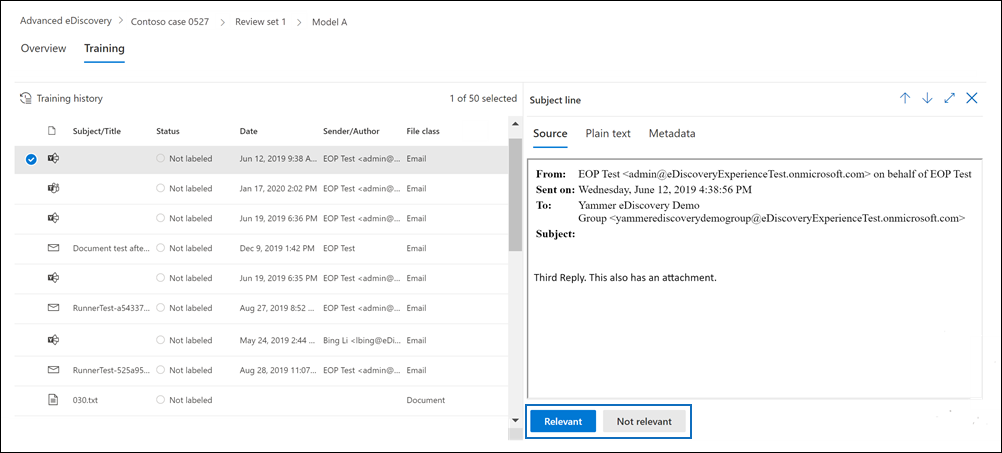
50개 항목 모두에 레이블을 지정한 후 마침을 선택합니다.
시스템에서 레이블 지정에서 "학습"하고 모델을 업데이트하는 데 몇 분 정도 걸립니다. 이 프로세스가 완료되면 예측 코딩 모델(미리 보기) 페이지에 모델에 대한 준비 상태 표시됩니다.
추가 학습 라운드 수행
첫 번째 학습 라운드를 수행한 후 이전 섹션의 단계에 따라 후속 학습 라운드를 수행할 수 있습니다. 유일한 차이점은 모델 개요 탭에서 업데이트되는 학습 라운드의 수입니다. 예를 들어 첫 번째 학습 라운드를 수행한 후 다음 학습 라운드 시작을 선택하여 두 번째 학습 라운드를 시작할 수 있습니다. 그리고 등등.
각 학습 라운드(진행 중인 학습과 완료된 학습 모두)가 모델의 학습 탭에 표시됩니다. 학습 라운드를 선택하면 라운드에 대한 정보와 메트릭이 있는 플라이아웃 페이지가 표시됩니다.
학습 라운드를 수행한 후 발생하는 작업
첫 번째 학습 라운드를 수행한 후 다음 작업을 수행하는 작업이 시작됩니다.
학습 집합의 40개 항목에 레이블을 지정한 방법에 따라 모델은 레이블 지정을 통해 학습하고 더 정확하게 업데이트합니다.
그런 다음, 모델은 전체 검토 집합의 각 항목을 처리하고 0 (관련 없음)과 1 (관련) 사이의 예측 점수를 할당합니다.
모델은 학습 라운드 중에 레이블을 지정한 컨트롤 집합의 10개 항목에 예측 점수를 할당합니다. 모델은 이러한 10개 항목의 예측 점수를 학습 라운드 중에 항목에 할당한 실제 레이블과 비교합니다. 이 비교에 따라 모델은 모델의 예측 성능을 평가하기 위해 다음 분류( 제어 집합 혼동 행렬이라고 함)를 식별합니다.
| Label | 모델은 항목이 관련성이 있다고 예측합니다. | 모델은 항목이 관련이 없음을 예측합니다. |
|---|---|---|
| 검토자 레이블 항목 관련 항목 | 진양성 | 가양성 |
| 검토자 레이블 항목이 관련이 없음 | 가음성 | 참 음수 |
이러한 비교에 따라 모델은 F 점수, 정밀도 및 회수 메트릭에 대한 값과 각 메트릭에 대한 오차 범위를 파생합니다. 이러한 모델 성능 메트릭에 대한 점수는 학습 라운드의 플라이아웃 페이지에 표시됩니다. 이러한 메트릭에 대한 설명은 예측 코딩 참조를 참조하세요.
- 마지막으로 모델은 다음 학습 라운드에 사용할 다음 50개 항목을 결정합니다. 이번에는 모델이 컨트롤 집합에서 20개 항목과 검토 집합의 30개 새 항목을 선택하고 다음 라운드에 대한 학습 집합으로 지정할 수 있습니다. 다음 학습 라운드에 대한 샘플링은 균일하게 샘플링되지 않습니다. 모델은 검토 집합의 항목 샘플링 선택을 최적화하여 예측이 모호한 항목을 선택합니다. 즉, 예측 점수가 0.5 범위에 있습니다. 이 프로세스를 편향된 선택이라고 합니다.
후속 학습 라운드를 수행한 후 발생하는 작업
첫 번째 학습 라운드 이후 후속 학습 라운드를 수행한 후 모델은 다음 작업을 수행합니다.
- 모델은 해당 학습 라운드의 학습 집합에 적용한 레이블을 기반으로 업데이트됩니다.
- 시스템은 컨트롤 집합의 항목에 대한 모델의 예측 점수를 평가하고 점수가 컨트롤 집합의 항목에 레이블을 지정하는 방법과 일치하는지 여부를 검사. 평가는 모든 학습 라운드에 대해 컨트롤 집합의 레이블이 지정된 모든 항목에 대해 수행됩니다. 이 평가의 결과는 모델의 개요 탭에 있는 dashboard 통합됩니다.
- 업데이트된 모델은 검토 집합의 모든 항목을 다시 처리하고 각 항목에 업데이트된 예측 점수를 할당합니다.
다음 단계
첫 번째 학습 라운드를 수행한 후 더 많은 학습 라운드를 수행하거나 모델의 예측 점수 필터를 검토 집합에 적용하여 모델이 관련 있거나 관련이 없는 것으로 예측한 항목을 볼 수 있습니다. 자세한 내용은 검토 집합에 예측 점수 필터 적용을 참조하세요.