Salin data ke atau dari Azure Data Lake Storage Gen1 menggunakan Azure Data Factory atau Azure Synapse Analytics
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Artikel ini menguraikan cara menyalin data ke dan dari Azure Data Lake Storage Gen1. Untuk mempelajari lebih lanjut, baca artikel pengantar untuk Azure Data Factory atau Azure Synapse Analytics.
Catatan
Azure Data Lake Storage Gen1 dihentikan pada 29 Februari 2024. Silakan migrasikan ke konektor Azure Data Lake Storage Gen2. Lihat artikel ini untuk panduan migrasi Azure Data Lake Storage Gen1.
Kemampuan yang didukung
Konektor Azure Data Lake Storage Gen1 ini didukung untuk kemampuan berikut:
| Kemampuan yang didukung | IR |
|---|---|
| Salin aktivitas (sumber/sink) | (1) (2) |
| Memetakan aliran data (sumber/sink) | (1) |
| Aktivitas pencarian | (1) (2) |
| Aktivitas GetMetadata | (1) (2) |
| Aktivitas penghapusan | (1) (2) |
① Runtime integrasi Azure ② Runtime integrasi yang dihost sendiri
Secara khusus, dengan konektor ini Anda dapat:
- Menyalin file dengan menggunakan salah satu metode autentikasi berikut: perwakilan layanan atau identitas terkelola untuk sumber daya Azure.
- Menyalin file sebagaimana adanya atau memilah atau menghasilkan file dengan format file yang didukung dan kodek pemadatan.
- Pertahankan ACL saat menyalin ke Azure Data Lake Storage Gen2.
Penting
Jika Anda menyalin data dengan menggunakan runtime integrasi yang dihost sendiri, konfigurasikan firewall perusahaan untuk memungkinkan lalu lintas outbound ke <ADLS account name>.azuredatalakestore.net dan login.microsoftonline.com/<tenant>/oauth2/token di port 443. Yang terakhir adalah Layanan Token Keamanan Azure yang perlu dikomunikasikan oleh runtime integrasi untuk mendapatkan token akses.
Memulai
Tip
Untuk mempelajari cara menggunakan konektor Azure Data Lake Storage, lihat Memuat data ke Azure Data Lake Storage.
Untuk melakukan aktivitas Salin dengan alur, Anda dapat menggunakan salah satu alat atau SDK berikut:
- Alat Penyalinan Data
- Portal Microsoft Azure
- SDK .NET
- SDK Python
- Azure PowerShell
- REST API
- Templat Azure Resource Manager
Membuat layanan tertaut ke Azure Data Lake Storage Gen1 menggunakan UI
Gunakan langkah-langkah berikut untuk membuat layanan tertaut ke Azure Data Lake Storage Gen1 di UI portal Azure.
Telusuri ke tab Kelola di ruang kerja Azure Data Factory atau Synapse Anda dan pilih Layanan Tertaut, lalu pilih Baru:
Cari Azure Data Lake Storage Gen1 lalu pilih konektor Azure Data Lake Storage Gen1.

Konfigurasikan detail layanan, uji koneksi, dan buat layanan tertaut baru.



Detail konfigurasi konektor
Bagian berikut ini menyediakan informasi tentang properti yang digunakan untuk menentukan entitas khusus untuk Azure Data Lake Store Gen1.
Properti layanan tertaut
Properti berikut ini didukung untuk layanan tertaut Azure Data Lake Storage:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti type harus diatur ke AzureDataLakeStore. |
Ya |
| dataLakeStoreUri | Informasi tentang akun Azure Data Lake Storage. Informasi ini menggunakan salah satu format berikut: https://[accountname].azuredatalakestore.net/webhdfs/v1 atau adl://[accountname].azuredatalakestore.net/. |
Ya |
| subscriptionId | ID langganan Azure tempat akun Data Lake Storage berada. | Diperlukan untuk sink |
| resourceGroupName | Nama grup sumber daya Azure tempat akun Data Lake Storage berada. | Diperlukan untuk sink |
| connectVia | Runtime integrasi yang akan digunakan untuk menyambungkan ke penyimpanan data. Anda dapat menggunakan runtime integrasi Azure atau runtime integrasi yang dihost sendiri jika penyimpanan data Anda berada di jaringan pribadi. Jika properti ini tidak ditentukan, runtime integrasi Azure default akan digunakan. | No |
Menggunakan autentikasi perwakilan layanan
Untuk menggunakan autentikasi perwakilan layanan, ikuti langkah-langkah berikut ini.
Daftarkan entitas aplikasi di ID Microsoft Entra dan berikan akses ke Data Lake Store. Untuk langkah-langkah terperinci, lihat Autentikasi layanan ke layanan. Catat nilai berikut, yang Anda gunakan untuk menentukan layanan tertaut:
- ID aplikasi
- Kunci Aplikasi
- ID Penyewa
Berikan izin yang tepat kepada perwakilan layanan. Lihat contoh tentang cara kerja izin dalam Data Lake Storage Gen1 dari Kontrol akses di Azure Data Lake Storage Gen1.
- Sebagai sumber: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Baca untuk file yang akan disalin. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default. Tidak ada persyaratan untuk kontrol akses tingkat akun (IAM).
- Sebagai sink: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Tulis untuk folder sink. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default.
Berikut adalah properti yang didukung:
| Properti | Deskripsi | Wajib diisi |
|---|---|---|
| servicePrincipalId | Menentukan ID klien aplikasi. | Ya |
| servicePrincipalKey | Tentukan kunci aplikasi. Tandai bidang ini sebagai SecureString untuk menyimpannya dengan aman, atau referensikan rahasia yang disimpan di Azure Key Vault. |
Ya |
| penyewa | Tentukan informasi penyewa, seperti nama domain atau ID penyewa, tempat aplikasi Anda berada. Anda dapat mengambilnya dengan mengarahkan mouse ke sudut kanan atas portal Microsoft Azure. | Ya |
| azureCloudType | Untuk autentikasi perwakilan layanan, tentukan jenis lingkungan cloud Azure tempat aplikasi Microsoft Entra Anda didaftarkan. Nilai yang diizinkan adalah AzurePublic, AzureChina, AzureUsGovernment, dan AzureGermany. Secara default, lingkungan cloud layanan digunakan. |
No |
Contoh:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Menggunakan autentikasi identitas terkelola yang ditetapkan sistem
Pabrik data atau ruang kerja Synapse dapat dikaitkan dengan identitas terkelola yang ditetapkan sistem, yang mewakili layanan untuk autentikasi. Anda dapat langsung menggunakan identitas terkelola yang ditetapkan sistem ini untuk autentikasi Data Lake Store, sama seperti menggunakan perwakilan layanan Anda sendiri. Hal ini memungkinkan pabrik yang ditunjuk ini untuk mengakses dan menyalin data ke atau dari Data Lake Store.
Untuk menggunakan autentikasi identitas terkelola, ikuti langkah-langkah berikut.
Ambil informasi identitas terkelola yang ditetapkan sistem dengan menyalin nilai "ID Aplikasi Identitas Layanan" yang dihasilkan beserta pabrik atau ruang kerja Synapse Anda.
Berikan akses identitas terkelola yang ditetapkan sistem ke Data Lake Store. Lihat contoh tentang cara kerja izin dalam Data Lake Storage Gen1 dari Kontrol akses di Azure Data Lake Storage Gen1.
- Sebagai sumber: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Baca untuk file yang akan disalin. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default. Tidak ada persyaratan untuk kontrol akses tingkat akun (IAM).
- Sebagai sink: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Tulis untuk folder sink. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default.
Anda tidak perlu menentukan properti apa pun selain informasi umum Data Lake Store di layanan tertaut.
Contoh:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Menggunakan autentikasi identitas terkelola yang ditetapkan pengguna
Sebuah pabrik data dapat ditetapkan dengan satu atau beberapa identitas terkelola yang ditetapkan pengguna. Anda dapat menggunakan identitas terkelola yang ditetapkan pengguna ini untuk autentikasi penyimpanan Blob, yang memungkinkan untuk mengakses dan menyalin data dari atau ke Data Lake Store. Untuk mempelajari lebih lanjut tentang identitas terkelola untuk sumber daya Azure, lihat Identitas terkelola untuk sumber daya Azure
Untuk menggunakan autentikasi identitas terkelola yang ditetapkan pengguna, ikuti langkah-langkah berikut:
Buat satu atau beberapa identitas terkelola yang ditetapkan pengguna dan berikan akses ke Azure Data Lake. Lihat contoh tentang cara kerja izin dalam Data Lake Storage Gen1 dari Kontrol akses di Azure Data Lake Storage Gen1.
- Sebagai sumber: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Baca untuk file yang akan disalin. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default. Tidak ada persyaratan untuk kontrol akses tingkat akun (IAM).
- Sebagai sink: Di Data explorer>Akses, berikan setidaknya izin Jalankan untuk SEMUA folder upstram termasuk akarnya, bersama dengan izin Tulis untuk folder sink. Anda bisa memilih untuk menambahkan ke Folder ini dan semua elemen anak untuk rekursif, dan menambahkan sebagai izin akses dan entri izin default.
Tetapkan satu atau beberapa identitas terkelola yang ditetapkan pengguna ke pabrik data Anda dan buat info masuk untuk setiap identitas terkelola yang ditetapkan pengguna.
Properti berikut ini didukung:
| Properti | Deskripsi | Wajib diisi |
|---|---|---|
| informasi masuk | Tentukan identitas terkelola yang ditetapkan pengguna sebagai objek kredensial. | Ya |
Contoh:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Properti himpunan data
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan himpunan data, lihat artikel Himpunan Data.
Azure Data Factory mendukung jenis format file berikut. Lihat setiap artikel untuk mengetahui cara melakukan pengaturan berbasis format.
- Format Avro
- Format Biner
- Format teks terpisah
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Properti berikut ini didukung untuk Azure Data Lake Storage Gen1 di bawah pengaturan location dalam himpunan data berbasis format:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis di bawah location dalam himpunan data harus diatur ke AzureDataLakeStoreLocation. |
Ya |
| folderPath | Jalur ke folder. Jika Anda ingin menggunakan kartubebas untuk memfilter folder, lewati pengaturan ini dan tentukan dalam pengaturan sumber aktivitas. | No |
| fileName | Nama file di folderPath yang diberikan. Jika Anda ingin menggunakan kartubebas untuk memfilter file, lewati pengaturan ini dan tentukan dalam pengaturan sumber aktivitas. | No |
Contoh:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Properti aktivitas salin
Untuk daftar lengkap bagian dan properti yang tersedia untuk menentukan aktivitas, lihat Alur. Bagian ini menyediakan daftar properti yang didukung oleh sumber dan sink Azure Data Lake Storage.
Azure Data Lake Storage sebagai sumber
Azure Data Factory mendukung jenis format file berikut. Lihat setiap artikel untuk mengetahui cara melakukan pengaturan berbasis format.
- Format Avro
- Format Biner
- Format teks terpisah
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Properti berikut ini didukung untuk Azure Data Lake Storage Gen1 di bawah pengaturan storeSettings dalam sumber salinan berbasis format:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis tipe di bawah storeSettings harus diatur ke AzureDataLakeStoreReadSettings. |
Ya |
| Menemukan file yang akan disalin: | ||
| OPSI 1: jalur statik |
Salin dari jalur folder/file yang diberikan dan ditentukan dalam himpunan data. Jika Anda ingin menyalin semua file dari folder, tentukan juga wildcardFileName sebagai *. |
|
| OPSI 2: rentang nama - listAfter |
Ambil folder/file yang namanya sesuai urutan abjad diawali dengan huruf setelah nilai ini (eksklusif). Opsi ini menggunakan filter sisi layanan untuk ADLS Gen1, yang memberikan performa yang lebih baik daripada filter kartubebas. Pabrik data menerapkan filter ini ke jalur yang ditentukan dalam himpunan data, dan hanya satu tingkat entitas yang didukung. Lihat contoh lainnya dalam Contoh filter rentang nama. |
No |
| OPSI 2: rentang nama - listBefore |
Ambil folder/file yang namanya sesuai urutan abjad diawali dengan huruf sebelum nilai ini (inksklusif). Opsi ini menggunakan filter sisi layanan untuk ADLS Gen1, yang memberikan performa yang lebih baik daripada filter kartubebas. Pabrik data menerapkan filter ini ke jalur yang ditentukan dalam himpunan data, dan hanya satu tingkat entitas yang didukung. Lihat contoh lainnya dalam Contoh filter rentang nama. |
No |
| OPSI 3: kartubebas - wildcardFolderPath |
Jalur folder dengan karakter kartubebas untuk memfilter folder sumber. Kartubebas yang diizinkan adalah: * (cocok dengan nol karakter atau lebih) dan ? (cocok dengan nol atau satu karakter); gunakan ^ untuk karakter escape jika nama folder Anda yang sebenarnya memiliki karakter kartubebas atau karakter escape ini di dalamnya. Lihat contoh lainnya dalam Contoh filter folder dan file. |
No |
| OPSI 3: kartubebas - wildcardFileName |
Nama file dengan karakter kartubebas di bawah folderPath/wildcardFolderPath yang diberikan untuk memfilter file sumber. Kartubebas yang diizinkan adalah: * (cocok dengan nol karakter atau lebih) dan ? (cocok dengan nol atau satu karakter); gunakan ^ untuk karakter escape jika nama file Anda yang sebenarnya memiliki karakter kartubebas atau karakter escape ini di dalamnya. Lihat contoh lainnya dalam Contoh filter folder dan file. |
Ya |
| OPSI 4: daftar file - fileListPath |
Mengindikasikan untuk menyalin set file yang diberikan. Arahkan ke file teks yang menyertakan daftar file yang ingin Anda salin, satu file per baris, yang merupakan jalur relatif ke jalur yang dikonfigurasi dalam himpunan data. Saat menggunakan opsi ini, jangan tentukan nama file dalam himpunan data. Lihat contoh lainnya dalam Contoh daftar file. |
No |
| Pengaturan tambahan: | ||
| recursive | Menunjukkan apakah data dibaca secara rekursif dari subfolder atau hanya dari folder yang ditentukan. Ketika rekursif diatur menjadi true dan sink-nya adalah penyimpanan berbasis file, folder atau subfolder kosong tidak disalin atau dibuat di sink. Nilai yang diizinkan adalah true (default) dan false. Properti ini tidak berlaku saat Anda mengonfigurasi fileListPath. |
No |
| deleteFilesAfterCompletion | Menunjukkan apakah file biner akan dihapus dari penyimpanan sumber setelah berhasil pindah ke penyimpanan tujuan. Penghapusan file adalah per file, jadi ketika aktivitas salin gagal, Anda akan melihat beberapa file telah disalin ke tujuan dan dihapus dari sumber, sementara yang lain masih tersisa di penyimpanan sumber. Properti ini hanya valid dalam skenario penyalinan file biner. Nilai default: false. |
No |
| modifiedDatetimeStart | Filter file berdasarkan atribut: Terakhir Diubah. File akan dipilih jika waktu modifikasi terakhir file tersebut besar dari atau sama dengan modifiedDatetimeStart dan kurang dari modifiedDatetimeEnd. Waktu diterapkan ke zona waktu UTC dalam format "2018-12-01T05:00:00Z". Properti dapat menjadi NULL, yang berarti tidak ada filter atribut file yang akan diterapkan ke himpunan data. Ketika modifiedDatetimeStart memiliki nilai tanggalwaktu tetapi modifiedDatetimeEnd null, itu berarti file yang atribut terakhir dimodifikasi lebih besar dari atau sama dengan nilai tanggalwaktu dipilih. Ketika modifiedDatetimeEnd memiliki nilai tanggalwaktu tetapi modifiedDatetimeStart null, itu berarti file yang atribut terakhir dimodifikasi kurang dari nilai tanggalwaktu dipilih.Properti ini tidak berlaku saat Anda mengonfigurasi fileListPath. |
No |
| modifiedDatetimeEnd | Sama dengan atas. | No |
| enablePartitionDiscovery | Untuk file yang dipartisi, tentukan apakah Anda akan memilah partisi dari jalur file dan menambahkannya sebagai kolom sumber tambahan. Nilai yang diperbolehkan adalah false (default) dan true. |
No |
| partitionRootPath | Ketika penemuan partisi diaktifkan, tentukan jalur akar absolut untuk membaca folder yang dipartisi sebagai kolom data. Jika tidak ditentukan, secara default, - Ketika Anda menggunakan jalur file dalam himpunan data atau daftar file pada sumber, jalur akar partisi adalah jalur yang dikonfigurasi dalam himpunan data. - Ketika Anda menggunakan filter folder kartubebas, jalur akar partisi adalah subpath sebelum wildcard pertama. Misalnya, dengan asumsi Anda mengonfigurasi jalur dalam himpunan data sebagai "root/folder/year=2020/month=08/day=27": - Jika Anda menentukan jalur akar partisi sebagai "root/folder/year=2020", aktivitas salin menghasilkan dua kolom month lagi dan day dengan nilai "08" dan "27" masing-masing, selain kolom di dalam file.- Jika jalur akar partisi tidak ditentukan, tidak ada kolom tambahan yang dihasilkan. |
No |
| maxConcurrentConnections | Batas atas koneksi bersamaan yang ditetapkan ke penyimpanan data selama eksekusi aktivitas. Menentukan nilai hanya saat Anda ingin membatasi koneksi bersamaan. | No |
Contoh:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Storage sebagai sink
Azure Data Factory mendukung jenis format file berikut. Lihat setiap artikel untuk mengetahui cara melakukan pengaturan berbasis format.
Properti berikut ini didukung untuk Azure Data Lake Storage Gen1 di pengaturan storeSettings dalam sink salinan berbasis format:
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis di bawah storeSettings harus diatur menjadi AzureDataLakeStoreWriteSettings. |
Ya |
| copyBehavior | Menentukan perilaku salin saat sumber berupa file dari penyimpanan data berbasis file. Nilai yang diperbolehkan adalah: - (default) PreserveHierarchy: Mempertahankan hierarki file di folder target. Jalur relatif dari file sumber ke folder sumber sama dengan jalur relatif file target ke folder target. - FlattenHierarchy: Semua file dari folder sumber berada di tingkat pertama folder target. File target memiliki nama yang ditulis secara otomatis. - MergeFiles: Menggabungkan semua file dari folder sumber dalam satu file. Jika nama file ditentukan, nama file yang digabungkan adalah nama yang ditentukan. Jika tidak, nama tersebut adalah nama file yang ditulis secara otomatis. |
No |
| expiryDateTime | Menentukan waktu kedaluwarsa file tertulis. Waktu diterapkan pada waktu UTC dalam format "2020-03-01T08:00:00Z". Secara default adalah NULL, yang berarti file tertulis tidak pernah kedaluwarsa. | No |
| maxConcurrentConnections | Batas atas koneksi bersamaan yang ditetapkan ke penyimpanan data selama eksekusi aktivitas. Menentukan nilai hanya saat Anda ingin membatasi koneksi bersamaan. | No |
Contoh:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Contoh filter rentang nama
Bagian ini menjelaskan perilaku filter rentang nama yang dihasilkan.
| Struktur sumber sampel | Konfigurasi | Hasil |
|---|---|---|
| akar a file.csv ax file2.csv ax.csv b file3.csv bx.csv c file4.csv cx.csv |
Dalam himpunan data: - Jalur folder: rootDi sumber aktivitas salin: - Daftar setelah: a- Daftar sebelum: b |
Kemudian file berikut disalin: akar ax file2.csv ax.csv b file3.csv |
Contoh filter folder dan file
Bagian ini menjelaskan perilaku yang dihasilkan dari jalur folder dan nama file dengan filter kartubebas.
| folderPath | fileName | recursive | Struktur folder sumber dan hasil filter (file dalam huruf tebal diambil) |
|---|---|---|---|
Folder* |
(Kosong, gunakan default) | salah | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(Kosong, gunakan default) | benar | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
salah | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
benar | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Contoh daftar file
Bagian ini menjelaskan perilaku yang dihasilkan dari penggunaan jalur daftar file di sumber aktivitas salin.
Dengan asumsi Anda memiliki struktur folder sumber berikut dan ingin menyalin file dengan bold:
| Struktur sumber sampel | Konten dalam FileListToCopy.txt | Konfigurasi |
|---|---|---|
| akar FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
Dalam himpunan data: - Jalur folder: root/FolderADi sumber aktivitas salin: - Jalur daftar file: root/Metadata/FileListToCopy.txt Jalur daftar file mengarah ke file teks di penyimpanan data yang sama yang menyertakan daftar file yang ingin Anda salin, satu file per baris dengan jalur relatif ke jalur yang dikonfigurasi dalam himpunan data. |
Contoh perilaku operasi salin
Bagian ini menjelaskan perilaku operasi salin yang dihasilkan untuk kombinasi nilai recursive dan copyBehavior yang berbeda.
| recursive | copyBehavior | Struktur folder sumber | Target yang dihasilkan |
|---|---|---|---|
| benar | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur yang sama dengan sumbernya: Folder1 File1 File2 Subfolder1 File3 File4 File5. |
| benar | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur berikut: Folder1 nama yang ditulis secara otomatis untuk File1 nama yang ditulis secara otomatis untuk File2 nama yang ditulis secara otomatis untuk File3 nama yang ditulis secara otomatis untuk File4 nama yang ditulis secara otomatis untuk File5 |
| benar | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur berikut: Folder1 konten File1 + File2 + File3 + File4 + File5 digabungkan ke dalam satu file, dengan nama file yang ditulis secara otomatis. |
| salah | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur berikut: Folder1 File1 File2 Subfolder1 dengan File3, File4, dan File5 tidak diambil. |
| salah | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur berikut: Folder1 nama yang ditulis secara otomatis untuk File1 nama yang ditulis secara otomatis untuk File2 Subfolder1 dengan File3, File4, dan File5 tidak diambil. |
| salah | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
Target Folder1 dibuat dengan struktur berikut: Folder1 konten File1 + File2 digabungkan ke dalam satu file, dengan nama file yang ditulis secara otomatis. nama yang ditulis secara otomatis untuk File1 Subfolder1 dengan File3, File4, dan File5 tidak diambil. |
Pertahankan ACL ke Data Lake Storage Gen2
Tip
Untuk menyalin data dari Azure Data Lake Storage Gen1 ke Gen2 secara umum, lihat Menyalin data dari Azure Data Lake Storage Gen1 ke Gen2 untuk panduan dan praktik terbaik.
Jika Anda ingin mereplikasi daftar kontrol akses (access control lists/ACL) bersama dengan file data saat Anda meningkatkan dari Data Lake Storage Gen1 ke Data Lake Storage Gen2, lihat Mempertahankan ACL dari Data Lake Storage Gen1.
Properti pemetaan aliran data
Saat Anda mentransformasi data dalam pemetaan alur data, Anda bisa membaca dan menulis file dari Azure Data Lake Storage Gen1 dalam format berikut:
Pengaturan format-spesifik terletak di dokumentasi untuk format tersebut. Untuk informasi selengkapnya, lihat Transformasi sumber dalam pemetaan aliran data dan Transformasi sink dalam pemetaan aliran data.
Transformasi sumber
Dalam transformasi sumber, Anda dapat membaca dari kontainer, folder, atau file individual di Azure Data Lake Storage Gen1. Tab Opsi sumber memungkinkan Anda mengelola cara file dibaca.

Jalur kartubebas: Menggunakan pola kartubebas akan menginstruksikan layanan untuk mengulang setiap folder dan file yang cocok dalam satu transformasi Sumber. Cara ini efektif untuk memproses beberapa file dalam satu aliran. Tambahkan beberapa pola kartubebas yang cocok dengan tanda + yang muncul saat Anda mengarahkan kursor ke pola kartubebas yang ada.
Dari kontainer sumber Anda, pilih serangkaian file yang cocok dengan satu pola. Hanya kontainer yang dapat ditentukan dalam himpunan data. Oleh karena itu, jalur kartubebas Anda juga harus menyertakan jalur folder Anda dari folder akar.
Contoh kartubebas:
*Mewakili sekumpulan karakter**Mewakili nesting direktori recursive?Menggantikan satu karakter[]Mencocokkan salah satu karakter lainnya dalam tanda kurung/data/sales/**/*.csvMendapatkan semua file csv di bawah /data/sales/data/sales/20??/**/Mendapatkan semua file secara rekursif dalam semua folder 20xx yang cocok/data/sales/*/*/*.csvMendapatkan file csv dua tingkat di bawah /data/sales/data/sales/2004/12/[XY]1?.csvMendapatkan semua file csv dari Desember 2004 yang dimulai dengan X atau Y, diikuti oleh 1, dan karakter tunggal apa pun
Jalur Akar Partisi: Jika Anda memiliki folder yang dipartisi di sumber file Anda dengan format key=value (misalnya, year=2019), maka Anda dapat menetapkan tingkat atas pohon folder partisi tersebut menjadi nama kolom di aliran stream data Anda.
Pertama, atur kartubebas untuk menyertakan semua jalur yang merupakan folder yang dipartisi ditambah file daun yang ingin Anda baca.
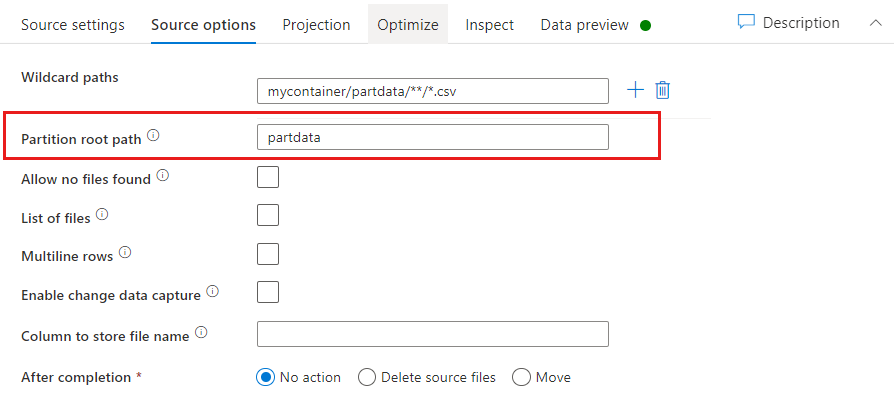
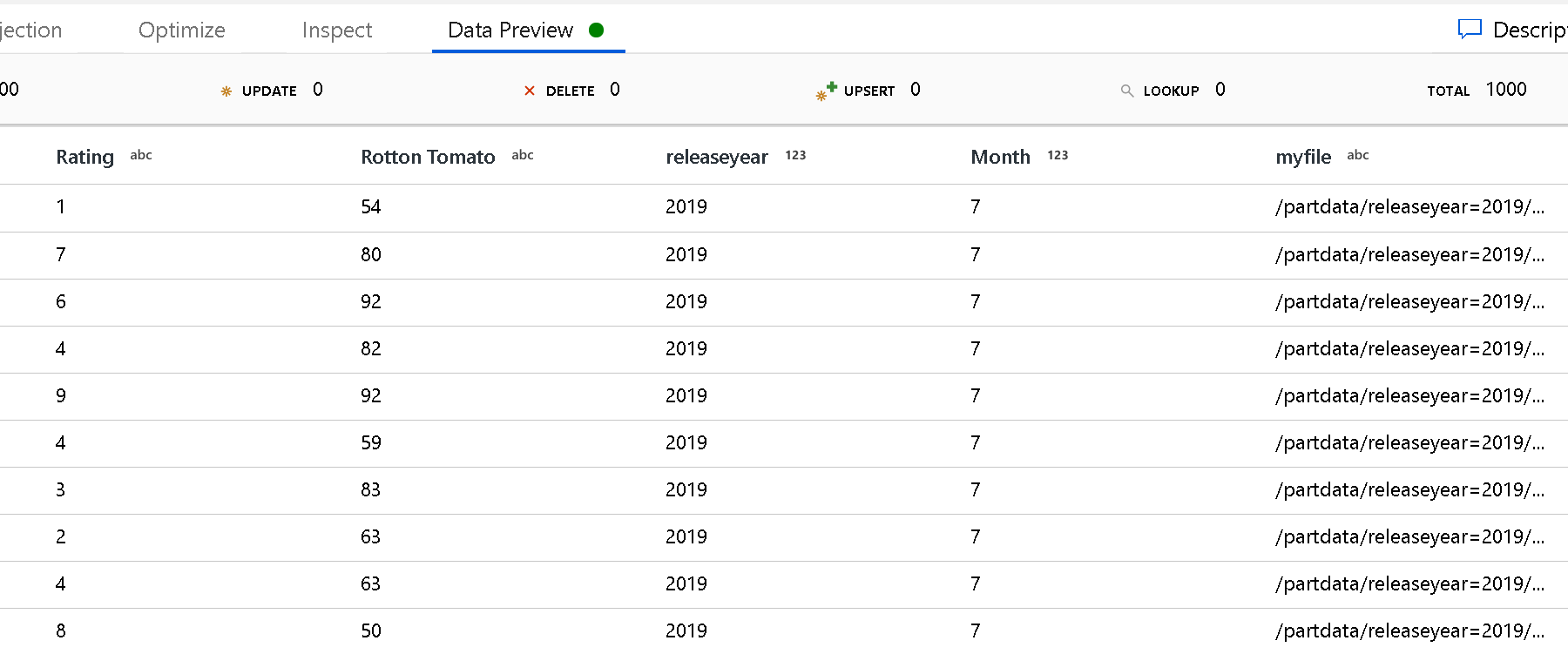
Gunakan pengaturan Jalur Akar Partisi untuk menentukan tingkat atas struktur folder. Saat Anda melihat konten data Anda melalui pratinjau data, Anda melihat bahwa layanan menambahkan partisi yang diselesaikan yang ditemukan di setiap tingkat folder Anda.
Daftar berkas: Daftar ini adalah set file. Buat file teks yang menyertakan daftar file jalur relatif untuk diproses. Arahkan ke file teks ini.
Kolom untuk menyimpan nama file: Simpan nama file sumber dalam kolom di data Anda. Masukkan nama kolom baru di sini untuk menyimpan untai (karakter) nama file.
Setelah selesai: Pilih untuk tidak melakukan apa pun pada file sumber setelah aliran data berjalan, menghapus file sumber, atau memindahkan file sumber. Jalur untuk perpindahan bersifat relatif.
Untuk memindahkan file sumber ke lokasi lain pasca-pemrosesan, pertama-tama pilih "Pindahkan" untuk operasi file. Kemudian, atur direktori "dari". Jika Anda tidak menggunakan kartubebas apa pun untuk jalur Anda, maka pengaturan "dari" adalah folder yang sama dengan folder sumber Anda.
Jika Anda memiliki jalur sumber dengan kartubebas, sintaks Anda terlihat seperti ini di bawah ini:
/data/sales/20??/**/*.csv
Anda dapat menentukan "dari" sebagai
/data/sales
Dan "untuk" sebagai
/backup/priorSales
Dalam hal ini, semua file yang bersumber di bawah /data/sales dipindahkan ke /backup/priorSales.
Catatan
Operasi file hanya berjalan ketika Anda memulai aliran data dari eksekusi alur (debug alur atau eksekusi alur) yang menggunakan aktivitas Jalankan Aliran Data dalam alur. Operasi file tidak berjalan dalam mode debug Aliran Data.
Filter berdasarkan terakhir diubah: Anda dapat memfilter file mana yang Anda proses dengan menentukan rentang tanggal file terakhir diubah. Semua waktu dalam format UTC.
Aktifkan ubah pengambilan data: Jika benar, Anda akan mendapatkan file baru atau yang diubah hanya dari eksekusi terakhir. Beban awal data snapshot penuh akan selalu didapat pada operasi pertama, diikuti dengan mengambil file baru atau yang diubah hanya dalam operasi berikutnya. Untuk detail selengkapnya, lihat Mengubah pengambilan data.

Properti sink
Dalam transformasi sink, Anda dapat menulis ke kontainer atau folder di Azure Data Lake Storage Gen1. Tab Pengaturan memungkinkan Anda mengelola bagaimana file ditulis.

Bersihkan folder: Menentukan apakah folder tujuan akan dihapus atau tidak sebelum data ditulis.
Opsi nama file: Menentukan bagaimana file tujuan dinamai dalam folder tujuan. Opsi nama file adalah:
- Default: Izinkan Spark untuk memberi nama file berdasarkan default PART.
- Pola: Masukkan pola yang menghitung file output Anda per partisi. Misalnya, pinjaman [n].csv membuat loans1.csv, loans2.csv, dan sebagainya.
- Per partisi: Masukkan satu nama file per partisi.
- Sebagai data dalam kolom: Atur file output menjadi nilai kolom. Jalur terhadap himpunan data relatif, namun tidak pada folder tujuan. Jika Anda memiliki jalur folder di himpunan data Anda, jalur tersebut akan ditimpa.
- Output ke file tunggal: Gabungkan file output yang dipartisi ke dalam file dengan nama tunggal. Jalur bersifat relatif terhadap folder himpunan data. Ketahuilah bahwa operasi penggabungan mungkin dapat gagal berdasarkan ukuran simpul. Opsi ini tidak disarankan untuk himpunan data besar.
Kuotasi semua: Menentukan apakah Anda akan menyertakan semua nilai dalam tanda kutip
Properti aktivitas pencarian
Untuk mempelajari detail tentang properti, lihat Aktivitas pencarian.
Properti aktivitas GetMetadata
Untuk mempelajari rincian tentang properti ini, periksa Aktivitas GetMetadata
Properti aktivitas penghapusan
Untuk mempelajari rincian tentang properti ini, periksa Aktivitas penghapusan
Model warisan
Catatan
Model berikut ini masih didukung apa adanya untuk kompatibilitas mundur. Anda disarankan untuk selanjutnya menggunakan model baru yang disebutkan di bagian di sebelumnya, dan antarmuka pengguna penulisan telah beralih untuk menghasilkan model baru.
Model himpunan data warisan
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis himpunan data harus diatur menjadi AzureDataLakeStoreFile. | Ya |
| folderPath | Jalur ke folder di Data Lake Storage. Jika tidak ditentukan, jalur mengarah ke akar. Filter kartubebas didukung. Kartubebas yang diizinkan adalah * (cocok dengan nol atau lebih karakter) dan ? (cocok dengan nol atau satu karakter). Gunakan ^ untuk karakter escape jika nama folder asli Anda memiliki karakter kartubebas atau karakter escape di dalamnya. Misalnya: rootfolder/subfolder/. Lihat contoh lainnya dalam Contoh filter folder dan file. |
No |
| fileName | Nama atau filter kartubebas untuk file di bawah "folderPath" yang ditentukan. Jika Anda tidak menentukan nilai untuk properti ini, himpunan data akan menunjuk ke semua file dalam folder. Kartubebas yang diizinkan untuk filter adalah * (cocok dengan nol atau lebih karakter) dan ? (cocok dengan nol atau satu karakter).- Contoh 1: "fileName": "*.csv"- Contoh 2: "fileName": "???20180427.txt"Gunakan ^ untuk karakter escape jika nama file asli Anda memiliki karakter kartubebas atau karakter escape di dalamnya.Ketika fileName tidak ditentukan untuk himpunan data output dan preserveHierarchy tidak ditentukan dalam sink aktivitas, aktivitas salin secara otomatis menghasilkan nama file dengan pola berikut:"Data.[ID GUID aktivitas yang berjalan].[GUID jika FlattenHierarchy].[format jika dikonfigurasi].[kompresi jika dikonfigurasi]", misalnya, "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Jika Anda menyalin dari sumber tabular dengan menggunakan nama tabel, bukan kueri, pola namanya adalah "[nama tabel].[format].[kompresi jika dikonfigurasi]", misalnya, "MyTable.csv". |
No |
| modifiedDatetimeStart | Filter file berdasarkan atribut Terakhir Diubah. File akan dipilih jika waktu modifikasi terakhir file tersebut besar dari atau sama dengan modifiedDatetimeStart dan kurang dari modifiedDatetimeEnd. Waktu diterapkan ke zona waktu UTC dalam format “2018-12-01T05:00:00Z”. Performa keseluruhan pergerakan data terpengaruh dengan mengaktifkan pengaturan ini ketika Anda ingin melakukan filter file dengan file jumlah besar. Properti dapat menjadi NULL, yang berarti tidak ada filter atribut file yang akan diterapkan ke himpunan data. Ketika modifiedDatetimeStart memiliki nilai tanggalwaktu tetapi modifiedDatetimeEnd adalah NULL, hal ini berarti file dengan nilai atribut yang terakhir diubah memiliki nilai lebih besar dari atau sama dengan nilai tanggalwaktu yang dipilih. Ketika modifiedDatetimeEnd memiliki nilai tanggalwaktu tetapi modifiedDatetimeStart adalah NULL, hal ini berarti file dengan nilai atribut yang terakhir diubah memiliki nilai lebih kecil dari nilai tanggalwaktu yang dipilih. |
No |
| modifiedDatetimeEnd | Filter file berdasarkan atribut Terakhir Diubah. File akan dipilih jika waktu modifikasi terakhir file tersebut besar dari atau sama dengan modifiedDatetimeStart dan kurang dari modifiedDatetimeEnd. Waktu diterapkan ke zona waktu UTC dalam format “2018-12-01T05:00:00Z”. Performa keseluruhan pergerakan data terpengaruh dengan mengaktifkan pengaturan ini ketika Anda ingin melakukan filter file dengan file jumlah besar. Properti dapat menjadi NULL, yang berarti tidak ada filter atribut file yang akan diterapkan ke himpunan data. Ketika modifiedDatetimeStart memiliki nilai tanggalwaktu tetapi modifiedDatetimeEnd adalah NULL, hal ini berarti file dengan nilai atribut yang terakhir diubah memiliki nilai lebih besar dari atau sama dengan nilai tanggalwaktu yang dipilih. Ketika modifiedDatetimeEnd memiliki nilai tanggalwaktu tetapi modifiedDatetimeStart adalah NULL, hal ini berarti file dengan nilai atribut yang terakhir diubah memiliki nilai lebih kecil dari nilai tanggalwaktu yang dipilih. |
No |
| format | Jika Anda ingin menyalin file sebagaimana adanya antar penyimpanan berbasis file (salinan biner), lewati bagian format di definisi himpunan data input dan output. Jika Anda ingin memilah atau membuat file dengan format tertentu, jenis format file berikut didukung: TextFormat, JsonFormat, AvroFormat, OrcFormat, dan ParquetFormat. Atur properti jenis berdasarkan format ke salah satu nilai ini. Untuk informasi selengkapnya, lihat bagian format Teks, Format JSON, format Avro, format Orc, dan format Parquet. |
Tidak (hanya untuk skenario salinan biner) |
| kompresi | Tentukan jenis dan tingkat kompresi untuk data. Untuk informasi selengkapnya, lihat Format file yang didukung dan kodek pemadatan. Jenis yang didukung adalah GZip, Deflate, BZip2, dan ZipDeflate. Level yang didukung adalah: Optimal dan Tercepat. |
No |
Tip
Untuk menyalin semua file di sebuah folder, tentukan folderPath saja.
Untuk menyalin satu file dengan nama tertentu, tentukan folderPath dengan bagian folder dan fileName dengan nama file.
Untuk menyalin subset file di sebuah folder, tentukan folderPath dengan bagian folder dan fileName dengan filter kartubebas.
Contoh:
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Model sumber aktivitas salin warisan
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti type sumber aktivitas salin harus diatur menjadi AzureDataLakeStoreSource. |
Ya |
| recursive | Menunjukkan apakah data dibaca secara rekursif dari subfolder atau hanya dari folder yang ditentukan. Ketika recursive diatur menjadi true dan sink adalah penyimpanan berbasis file, folder kosong atau subfolder tidak disalin atau dibuat di sink. Nilai yang diizinkan adalah true (default) dan false. |
No |
| maxConcurrentConnections | Batas atas koneksi bersamaan yang ditetapkan ke penyimpanan data selama eksekusi aktivitas. Menentukan nilai hanya saat Anda ingin membatasi koneksi bersamaan. | No |
Contoh:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Model sink aktivitas salin warisan
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti type sink aktivitas salin harus diatur menjadi AzureDataLakeStoreSink. |
Ya |
| copyBehavior | Menentukan perilaku salin saat sumber berupa file dari penyimpanan data berbasis file. Nilai yang diperbolehkan adalah: - (default) PreserveHierarchy: Mempertahankan hierarki file di folder target. Jalur relatif dari file sumber ke folder sumber sama dengan jalur relatif file target ke folder target. - FlattenHierarchy: Semua file dari folder sumber berada di tingkat pertama folder target. File target memiliki nama yang ditulis secara otomatis. - MergeFiles: Menggabungkan semua file dari folder sumber dalam satu file. Jika nama file ditentukan, nama file yang digabungkan adalah nama yang ditentukan. Jika tidak, nama file akan dihasilkan secara otomatis. |
No |
| maxConcurrentConnections | Batas atas koneksi bersamaan yang ditetapkan ke penyimpanan data selama eksekusi aktivitas. Menentukan nilai hanya saat Anda ingin membatasi koneksi bersamaan. | No |
Contoh:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Mengubah pengambilan data (pratinjau)
Azure Data Factory bisa mendapatkan file baru atau yang diubah hanya dari Azure Data Lake Storage Gen1 dengan mengaktifkan Aktifkan pengambilan data perubahan (Pratinjau) dalam pemetaan transformasi sumber aliran data. Dengan opsi konektor ini, Anda hanya dapat membaca file baru atau yang diperbarui dan menerapkan transformasi sebelum memuat data yang diubah ke dalam himpunan data tujuan pilihan Anda.
Pastikan Anda menjaga alur dan nama aktivitas tidak berubah, sehingga titik pemeriksaan selalu dapat direkam dari eksekusi terakhir untuk mendapatkan perubahan dari sana. Jika Anda mengubah nama alur atau nama aktivitas, titik pemeriksaan akan diatur ulang, dan Anda akan mulai dari awal dalam proses berikutnya.
Saat Anda mendebug alur, Aktifkan ubah pengambilan data (Pratinjau) juga berfungsi. Titik pemeriksaan diatur ulang saat Anda me-refresh browser selama eksekusi debug. Setelah puas dengan hasil dari eksekusi debug, Anda dapat menerbitkan dan memicu alur. Langkah ini akan selalu dimulai dari awal terlepas dari pos pemeriksaan sebelumnya yang direkam oleh eksekusi debug.
Di bagian pemantauan, Anda selalu memiliki kesempatan untuk menjalankan kembali alur. Saat Anda melakukannya, perubahan selalu diperoleh dari catatan titik pemeriksaan dalam eksekusi alur yang Anda pilih.
Konten terkait
Untuk daftar penyimpanan data yang didukung sebagai sumber dan sink oleh aktivitas salin, lihat penyimpanan data yang didukung.