टेक्स्ट पहचान प्रीबिल्ट मॉडल का उपयोग करें Power Automate
टेक्स्ट पहचान प्रीबिल्ट मॉडल छवियों और दस्तावेजों से मुद्रित और हस्तलिखित पाठ निकालता है। AI Builder इस मॉडल का उपयोग करके, आप ऐसे वर्कफ़्लो बना सकते हैं जो स्कैन किए गए दस्तावेज़ों, फ़ोटो और पीडीएफ से पाठ को स्वचालित रूप से संसाधित करते हैं, जिससे कुशल डेटा हैंडलिंग और अन्य अनुप्रयोगों के साथ एकीकरण संभव होता है। Power Automate
यह दस्तावेज़ टेक्स्ट पहचान प्रीबिल्ट मॉडल का उपयोग करने पर एक गाइड प्रदान करता है। Power Automate
प्रवाह आरंभ करें Power Automate
प्रवाह को आरंभ करना आपकी स्वचालित प्रक्रिया को स्थापित करने में पहला कदम है। Power Automate यह चरण आपको अपने प्रवाह के लिए ट्रिगर और प्रारंभिक इनपुट पैरामीटर परिभाषित करने की अनुमति देता है। जब आप आरंभ करते हैं, तो आप यह सुनिश्चित कर सकते हैं कि आपका प्रवाह सही ढंग से शुरू हो और इसमें टेक्स्ट पहचान कार्यों को कुशलतापूर्वक संसाधित करने के लिए आवश्यक जानकारी हो।
अपना प्रवाह आरंभ करने के लिए, इन चरणों का पालन करें:
Power Automateपर लॉग इन करें.
बाईं ओर नेविगेशन मेनू पर, मेरे प्रवाह का चयन करें, और फिर नया प्रवाह >तत्काल चरण का चयन करें.
अपने प्रवाह को नाम दें, मैन्युअल रूप से प्रवाह ट्रिगर करें के अंतर्गत इस प्रवाह को ट्रिगर करने का तरीका चुनें का चयन करें, और फिर बनाएँ का चयन करें।
विस्तृत करें मैन्युअल रूप से प्रवाह ट्रिगर करें, और फिर इनपुट प्रकार के रूप में +इनपुट जोड़ें>फ़ाइल का चयन करें.
+नया चरण>AI Builder चुनें, और फिर क्रियाओं की सूची में छवि या PDF दस्तावेज़ में पाठ पहचानें चुनें.
छवि इनपुट का चयन करें, और फिर डायनामिक सामग्री सूची से फ़ाइल सामग्री का चयन करें:

परिणामों को संसाधित करने के लिए, आप या तो संपूर्ण दस्तावेज़ पाठ, पृष्ठ पाठ, या दस्तावेज़ पाठ पंक्ति दर पंक्ति का उपयोग कर सकते हैं।
संपूर्ण दस्तावेज़ पाठ या पूर्ण पृष्ठ पाठ प्राप्त करें
यदि आपको संपूर्ण दस्तावेज़ पाठ या विशिष्ट पृष्ठ पाठ पर कोई कार्रवाई करने की आवश्यकता है, तो यह विकल्प उपयोगी है। पृष्ठ पाठ का उपयोग करने का एक उदाहरण तब है जब आप किसी सबस्ट्रिंग को खोजना चाहते हैं, या उसे डाउनस्ट्रीम क्रिया में पास करना चाहते हैं।
आप डायनामिक सामग्री सूची से दस्तावेज़ का पूर्ण पाठ का उपयोग करके सभी निकाले गए पाठ को टीम्स चैनल में पोस्ट कर सकते हैं.
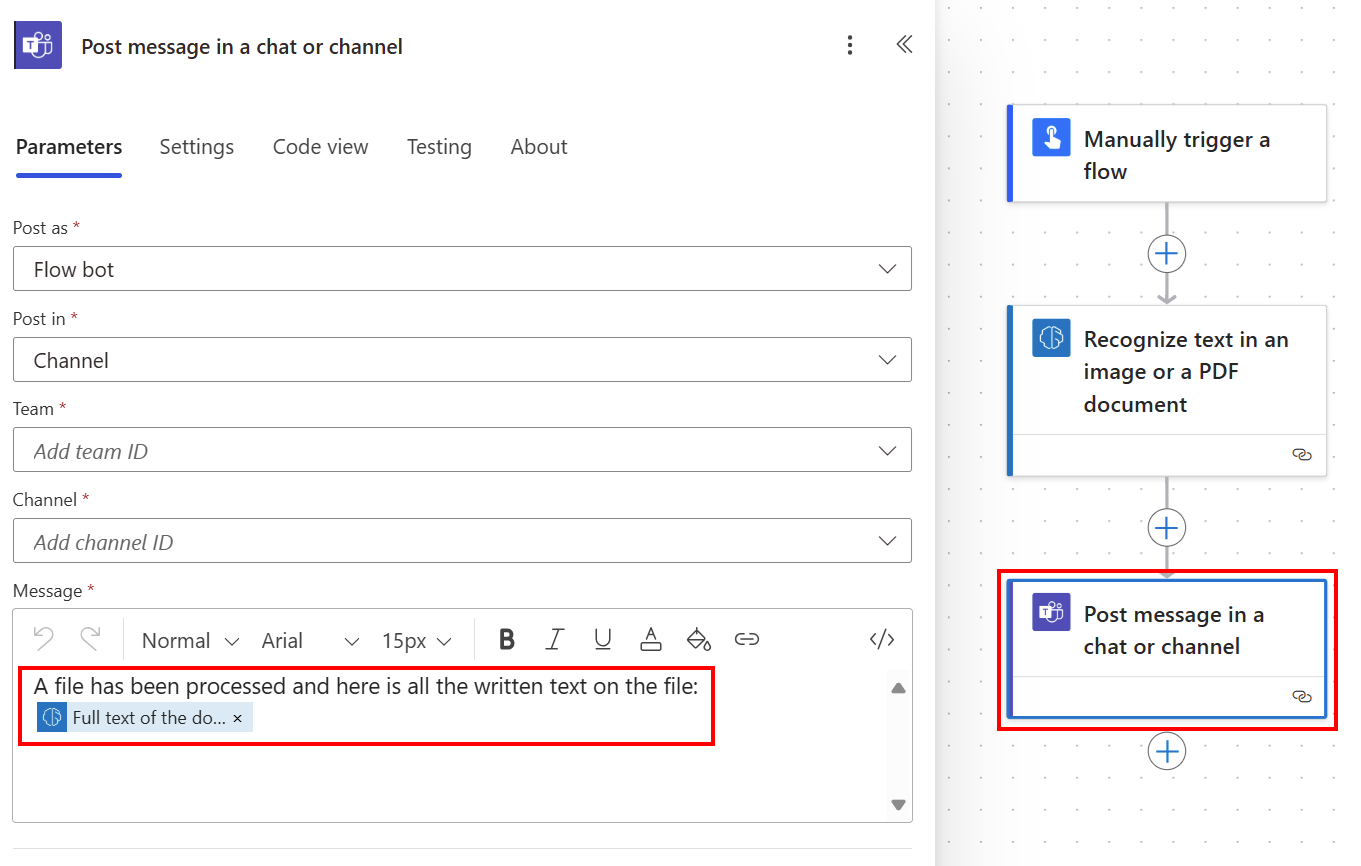
दस्तावेज़ का पाठ पंक्ति दर पंक्ति प्राप्त करें
यदि आपको पाठ की किसी विशिष्ट पंक्ति को अलग करना हो, या अपनी सुविधानुसार पाठ को पुनः स्वरूपित करना हो, तो दस्तावेज़ के पाठ को पंक्ति दर पंक्ति प्राप्त करना उपयोगी हो सकता है।
स्ट्रिंग वैरिएबल बनाने के लिए, +नया चरण>नियंत्रण का चयन करें, और फिर वैरिएबल आरंभ करें का चयन करें.
उदाहरण के लिए इसका नाम निकाला गया पाठ रखें।
+नया चरण>नियंत्रण का चयन करें, और फिर स्ट्रिंग चर में जोड़ें का चयन करें.
मूल्य फ़ील्ड में, डायनामिक सामग्री सूची से टेक्स्ट चुनें.
यह पृष्ठों की सूची में पंक्तियों के पाठ की सूची पढ़ते समय दो प्रत्येक पर लागू करें क्रियाओं को स्वचालित रूप से उत्पन्न करता है। फिर आप निकाले गए सभी टेक्स्ट को टीम्स चैनल में पोस्ट कर सकते हैं।
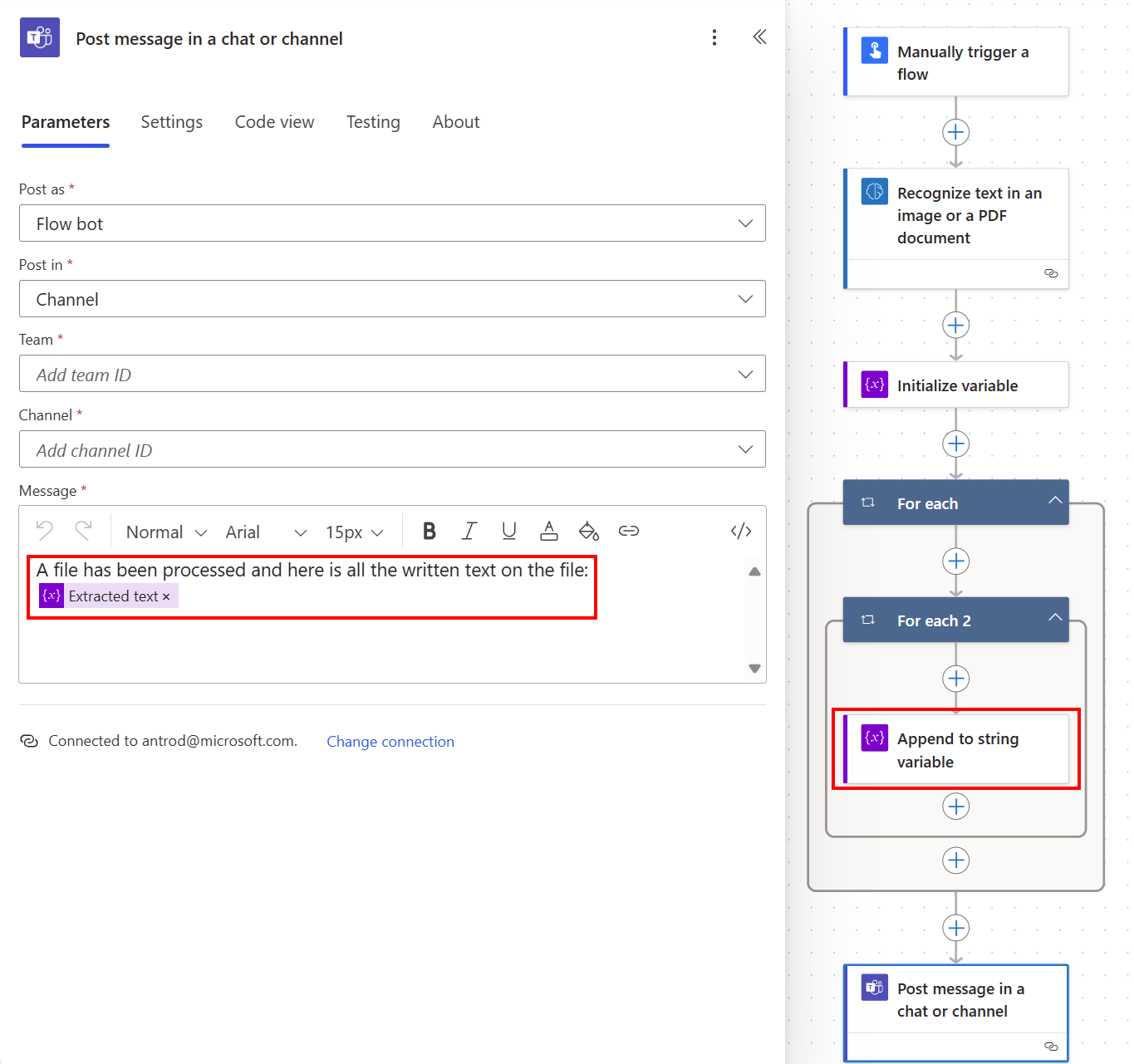
बधाई! आपने एक प्रवाह बनाया है जो टेक्स्ट पहचान मॉडल का उपयोग करता है। आप इस प्रवाह को तब तक जारी रख सकते हैं जब तक यह आपकी आवश्यकताओं के अनुरूप न हो जाए। अपने प्रवाह को आज़माने के लिए ऊपर दाईं ओर सहेजें चुनें, और फिर परीक्षण चुनें।
पैरामीटर्स
AI Builder में टेक्स्ट पहचान प्रीबिल्ट मॉडल में निम्नलिखित इनपुट और आउटपुट पैरामीटर शामिल हैं।
इनपुट
| Name | आवश्य | प्रकार | विवरण |
|---|---|---|---|
| छवि | हां | फ़ाइल | विश्लेषण हेतु छवि |
आउटपुट
पता लगाया गया पाठ पंक्तियों परिणाम सूची की उप सूची में एम्बेड किया गया है। आपको सबसे पहले सभी निम्नलिखित स्तंभों को देखने के लिए लाइनों कॉलम को प्रत्येक पर लागू करें कार्रवाई से चुनना होगा।
| नाम | प्रकार | विवरण |
|---|---|---|
| मूलपाठ | string | पाठ की पंक्ति वाले स्ट्रिंग्स का पता लगाया गया |
| पृष्ठ संख्या | string | पता लगाए गए पाठ की पृष्ठ संख्या |
| COORDINATES | तैरना | पता लगाए गए पाठ के निर्देशांक |
| दस्तावेज़ का पूर्ण पाठ | string | पूर्ण पाठ का पता चला |
| पृष्ठ का पूर्ण पाठ | string | पूर्ण पृष्ठ पाठ का पता चला |