استخدام أدوات Spark وApache Hive لتعليمات Visual Studio البرمجية
تعرف على كيفية استخدام Apache أدوات Spark وHive لرمز Visual Studio. استخدام الأدوات لإنشاء وتقديم وظائف دفعة Apache Hive، واستعلامات Hive التفاعلية، ومخطوطات PySpark المخصصة لـ Apache Spark. أولاً سنصف كيفية تثبيت أدوات Spark & Hive في Visual Studio تعليمة برمجية. بعد ذلك سنناقش كيفية تقديم الوظائف إلى أدوات Spark & Hive.
يمكن تثبيت أدوات Spark & Hive على الأنظمة الأساسية التي يدعمها رمز Visual Studio. لاحظ المتطلبات الأساسية التالية لأنظمة أساسية مختلفة.
المتطلبات الأساسية
العناصر التالية مطلوبة لإكمال الخطوات في هذه المقالة:
- مجموعة Azure HDInsight. لإنشاء مجموعة، راجع بدء استخدام HDInsight. أو استخدم مجموعة Spark and Hive التي تدعم نقطة نهاية Apache Livy.
- تعليمة Visual Studio البرمجية.
- Mono. مطلوب Mono فقط لـ Linux وmacOS.
- بيئة تفاعلية PySpark لرمز Visual Studio.
- دليل محلي. يستخدم هذا المقال
C:\HD\HDexample.
تثبيت أدوات Spark & Hive
بعد استيفاء المتطلبات الأساسية، يمكنك تثبيت أدوات Spark & Hive للتعليمات البرمجية Visual Studio باتباع الخطوات التالية:
فتح Visual Studio Code.
من شريط القوائم، انتقل إلى عرض>الإضافات.
في مربع البحث، أدخل Spark & Hive.
حدد Spark & Hive Tools من نتائج البحث، ثم حدد تثبيت:

حدد إعادة تحميل عند الضرورة.
فتح مجلد عمل
لفتح مجلد عمل وإنشاء ملف في التعليمات البرمجية Visual Studio اتبع الخطوات التالية:
من شريط القوائم، انتقل إلى ملف>فتح مجلد...>
C:\HD\HDexample، ثم حدد الزر تحديد مجلد. يظهر المجلد في طريقة العرض مستكشف على اليسار.في طريقة عرض المستكشف ، حدد
HDexampleالمجلد، ثم حدد أيقونة ملف جديد بجوار مجلد العمل:
قم بتسمية الملف الجديد باستخدام إما
.hql(استعلامات Hive) أو امتداد الملف.py(Spark script). يستخدم هذا المثال HelloWorld.hql.
مجموعة بيئة Azure
بالنسبة لمستخدم السحابة الوطني، اتبع هذه الخطوات لتعيين بيئة Azure أولاً، ثم استخدم الأمر Azure: تسجيل الدخول لتسجيل الدخول إلى Azure:
انتقل إلى ملف>التفضيلات>الإعدادات.
ابحث عن السلسلة التالية: Azure: Cloud.
حدد السحابة الوطنية من القائمة:

الاتصال بحساب Azure
قبل أن تتمكن من إرسال البرامج النصية إلى مجموعاتك من Visual Studio Code، يمكن للمستخدم إما تسجيل الدخول إلى اشتراك Azure، أو ربط مجموعة HDInsight. استخدم اسم مستخدم Ambari/كلمة المرور أو بيانات الاعتماد المنضمة إلى المجال لمجموعة ESP للاتصال بمجموعة HDInsight الخاصة بك. متابعة هذه الخطوات للاتصال مع Azure:
من شريط القوائم، انتقل إلى عرض > Command Palette... ، وأدخلAzure: تسجيل الدخول:

اتبع إرشادات تسجيل الدخول لتسجيل الدخول إلى Azure. بعد الاتصال، يظهر اسم حساب Azure على شريط المعلومات في أسفل إطار رمز Visual Studio.
ربط النظام
الرابط: Azure HDInsight
يمكنك ربط نظام مجموعة عادية باستخدام اسم مستخدم مُدار بواسطة Apache Ambari ، أو يمكنك ربط نظام مجموعة Hadoop آمنة لـ Enterprise Security Pack باستخدام اسم مستخدم مجال (مثل: such as user1@contoso.com).
من شريط القائمة، انتقل إلى View>Command Palette... ثم أدخل Spark / Hive: Link a Cluster.

حدد نوع المجموعة المرتبطة Azure HDInsight .
أدخل عنوان URL لمجموعة HDInsight.
أدخل اسم مستخدم Ambari الخاص بك ؛ الافتراضي هو admin.
أدخل كلمة مرور أمباري الخاصة بك.
حدد نوع نظام المجموعة.
قم بتعيين اسم عرض المجموعة (اختياري).
راجع عرض الإخراج للتحقق.
إشعار
يتم استخدام اسم المستخدم وكلمة المرور المرتبطين إذا قامت المجموعة بتسجيل الدخول إلى اشتراك Azure وربطها بمجموعة.
الارتباط: نقطة نهاية Livy العامة
من شريط القائمة، انتقل إلى View>Command Palette... ثم أدخل Spark / Hive: Link a Cluster.
حدد نوع المجموعة المرتبط نقطة نهاية Livy العامة.
أدخل نقطة نهاية Livy العامة. على سبيل المثال: http://10.172.41.42:18080.
حدد نوع التفويض أساسي أو لا شيء. إذا حددت أساسي:
أدخل اسم مستخدم Ambari الخاص بك ؛ الافتراضي هو admin.
أدخل كلمة مرور أمباري الخاصة بك.
راجع عرض الإخراج للتحقق.
سرد نظام المجموعات
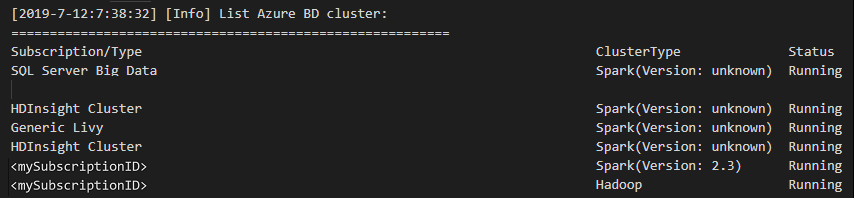
من شريط القائمة، انتقل إلى View>Command Palette...، ثم أدخل Spark / Hive: List Cluster.
حدد الاشتراك الذي تريده.
راجع عرض الإخراج. تُظهر طريقة العرض هذه المجموعة (أو المجموعات) المرتبطة وكل نظام المجموعة ضمن اشتراك Azure الخاص بك:
تعيين المجموعة الافتراضية
HDexampleأعد فتح المجلد الذي تمت مناقشته سابقا، إذا تم إغلاقه.حدد ملف HelloWorld.hql الذي تم إنشاؤه مسبقاً. يفتح في محرر النص.
انقر بزر الماوس الأيمن فوق محرر البرنامج النصي، ثم حدد Spark / Hive: Set Default Cluster.
اتصل بحسابك في Azure، أو اربط مجموعة إذا لم تكن قد فعلت ذلك بعد.
حدد نظام مجموعة كمجموعة افتراضية لملف البرنامج النصي الحالي. تقوم الأدوات تلقائياً بتحديث ملف التكوين .VSCode\settings.json:

إرسال استعلامات Hive التفاعلية ونصوص دُفعات Hive
باستخدام Spark & أدوات الخلية للتعليمات البرمجية Visual Studio، يمكنك إرسال استعلامات خلية تفاعلية ونصوص دفعة الخلية إلى مجموعاتك.
HDexampleأعد فتح المجلد الذي تمت مناقشته سابقا، إذا تم إغلاقه.حدد ملف HelloWorld.hql الذي تم إنشاؤه مسبقاً. يفتح في محرر النص.
انسخ التعليمة البرمجية التالي والصقه في ملف Hive الخاص بك، ثم احفظه:
SELECT * FROM hivesampletable;اتصل بحسابك في Azure، أو اربط مجموعة إذا لم تكن قد فعلت ذلك بعد.
انقر بزر الماوس الأيمن فوق محرر البرنامج النصي وحدد Hive: Interactive لإرسال الاستعلام، أو استخدم اختصار لوحة المفاتيح Ctrl + Alt + I. حدد Hive: Batch لإرسال البرنامج النصي، أو استخدم اختصار لوحة المفاتيح Ctrl + Alt + H.
إذا لم تكن قد حددت مجموعة افتراضية، فحدد مجموعة. تتيح لك الأدوات أيضاً إرسال مجموعة من التعليمات البرمجية بدلاً من ملف البرنامج النصي بأكمله باستخدام قائمة السياق. بعد لحظات قليلة، تظهر نتائج الاستعلام في علامة تبويب جديدة:

لوحة النتائج: يمكنك حفظ النتيجة بأكملها كملف CSV أو JSON أو Excel في مسار محلي أو تحديد أسطر متعددة فقط.
لوحة الرسائل: عند تحديد رقم السطر، فإنه ينتقل إلى السطر الأول من البرنامج النصي قيد التشغيل.
إرسال استعلامات PySpark التفاعلية
المتطلبات الأساسية لـPyspark التفاعلي
لاحظ هنا أن إصدار ملحق Jupyter (ms-jupyter): v2022.1.1001614873 وإصدار ملحق Python (ms-python): v2021.12.1559732655 وPython 3.6.x و3.7.x مطلوبة للاستعلامات التفاعلية ل HDInsight PySpark.
يمكن للمستخدمين أداء PySpark تفاعلي بالطرق التالية.
استخدام الأمر التفاعلي PySpark في ملف PY
استخدام الأمر التفاعلي PySpark لإرسال الاستعلامات، اتبع الخطوات التالية:
HDexampleأعد فتح المجلد الذي تمت مناقشته سابقا، إذا تم إغلاقه.إنشاء ملف HelloWorld.py جديد، باتباع الخطوات السابقة.
انسخ والصق المحتويات التالية في الملف:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])يتم عرض المطالبة لتثبيت PySpark/Synapse Pyspark kernel في الزاوية اليمنى السفلى من النافذة. يمكنك النقر على زر Install للمتابعة للمنشآت PySpark / Synapse Pyspark؛ أو انقر على زر تخطي لتجاوز هذه الخطوة.

إذا كنت بحاجة إلى تثبيته في وقت لاحق، يمكنك الانتقال إلى File>Preference>Settings ثم إلغاء اختيار HDInsight: Enable Skip Pyspark Installation في الإعدادات.

إذا نجح التثبيت في الخطوة 4، فسيتم عرض مربع الرسالة "تم تثبيت PySpark بنجاح" في الركن الأيمن السفلي من النافذة. انقر على زر إعادة تحميل لإعادة تحميل النافذة.

من شريط القوائم، انتقل إلى عرض>لوحة الأوامر... أو استخدم اختصار لوحة مفاتيح Shift + Ctrl + P، وأدخل Python: حدد مترجم لبدء تشغيل Jupyter Server.

حدد خيار "Python" أدناه.

من شريط القوائم، انتقل إلى عرض>لوحة الأوامر... أو استخدم اختصار لوحة مفاتيح Shift + Ctrl + P، وأدخل Developer: أعد تحميل Window.

اتصل بحسابك في Azure، أو اربط مجموعة إذا لم تكن قد فعلت ذلك بعد.
حدد كل التعليمات البرمجية، وانقر بزر الماوس الأيمن فوق محرر البرنامج النصي، وحدد Spark: PySpark Interactive / Synapse: Pyspark Interactive لإرسال الاستعلام.

حدد نظام المجموعة إذا لم تحدد نظام المجموعة الافتراضية. بعد لحظات قليلة، تظهر نتائج Python Interactive في علامة تبويب جديدة. انقر فوق PySpark لتحويل kernel إلى PySpark / Synapse Pyspark، وسيتم تشغيل التعليمة البرمجية بنجاح. إذا كنت تريد التبديل إلى Synapse Pyspark kernel، فيوصى بتعطيل الإعدادات التلقائية في مدخل Microsoft Azure. وإلا قد يستغرق وقتاً طويلاً لتنبيه الكتلة وتعيين synapse kernel لأول مرة استخدام. إذا كانت الأدوات تتيح لك أيضاً إرسال نظام مجموعة من التعليمات البرمجية بدلاً من ملف البرنامج النصي بأكمله باستخدام قائمة السياق:

أدخل ٪٪ info، ثم اضغط على Shift + Enter لعرض معلومات الوظيفة (اختياري):

تدعم الأداة أيضاً استعلام Spark SQL:

إجراء استعلام تفاعلي في ملف PY باستخدام تعليق #٪٪
أضف #%% قبل Py code للحصول على تجربة استخدام الكمبيوتر المحمول.

انقر على تشغيل الخلية. بعد لحظات قليلة، تظهر نتائج Python Interactive في علامة تبويب جديدة. انقر فوق PySpark لتبديل النواة إلى PySpark/Synapse PySpark، ثم انقر فوق تشغيل الخلية مرة أخرى، وسيتم تشغيل التعليمات البرمجية بنجاح.

الاستفادة من دعم IPYNB من تمديد Python
يمكنك إنشاء Jupyter Notebook عن طريق الأمر من لوحة الأوامر أو عن طريق إنشاء ملف جديد
.ipynbفي مساحة العمل الخاصة بك. لمزيد من المعلومات، راجع العمل مع دفاتر ملاحظات Jupyter في Visual Studio Codeانقر فوق الزر Run cell ، واتبع المطالبات لتعيين تجمع spark الافتراضي (نقترح عليك تعيين نظام المجموعة/التجمع الافتراضي في كل مرة قبل فتح دفتر ملاحظات) ثم إعادة تحميل النافذة.

انقر فوق PySpark لتبديل kernel إلى PySpark / Synapse Pyspark ، ثم انقر فوق تشغيل الخلية، وبعد فترة، سيتم عرض النتيجة.

إشعار
بالنسبة لخطأ تثبيت Synapse PySpark، حيث لن يتم الحفاظ على تبعيته بعد الآن من قبل فريق آخر، لن يتم الحفاظ على هذا بعد الآن أيضًا. إذا حاولت استخدام Synapse Pyspark التفاعلي، فيرجى التبديل لاستخدام Azure Synapse Analytics بدلا من ذلك. وهو تغيير على المدى الطويل.
إرسال وظيفة دفعية PySpark
HDexampleأعد فتح المجلد الذي ناقشته سابقا، إذا كان مغلقا.إنشاء ملف BatchFile.py جديد، باتباع الخطوات السابقة.
انسخ والصق المحتويات التالية في الملف:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()اتصل بحسابك في Azure، أو اربط مجموعة إذا لم تكن قد فعلت ذلك بعد.
انقر بزر الماوس الأيمن فوق محرر البرنامج النصي، ثم حدد Spark: PySpark Batch أو *Synapse: PySpark Batch*.
حدد مجموعة/تجمع شرارة لإرسال مهمة PySpark الخاصة بك إلى:

بعد إرسال مهمة Python، تظهر سجلات الإرسال في نافذة OUTPUT في Visual Studio Code. يتم أيضاً عرض عنوان URL لواجهة Spark UI وعنوان URL لواجهة مستخدم Yarn. إذا قمت بإرسال الوظيفة المجمعة إلى تجمع Apache Spark، فسيتم أيضاً عرض عنوان URL لواجهة مستخدم سجل Spark وعنوان URL لواجهة مستخدم تطبيق Spark Job. يمكنك فتح عنوان URL في متصفح الويب لتتبع حالة الوظيفة.
التكامل مع HDInsight Identity Broker (HIB)
اتصل بمجموعة HDInsight ESP الخاصة بك باستخدام ID Broker (HIB)
يمكنك اتباع الخطوات العادية لتسجيل الدخول إلى اشتراك Azure للاتصال بمجموعة HDInsight ESP باستخدام ID Broker (HIB). بعد تسجيل الدخول، سترى قائمة المجموعة في مستكشف Azure. لمزيد من الإرشادات، راجع الاتصال بمجموعة HDInsight.
قم بتشغيل مهمة Hive/PySpark على مجموعة HDInsight ESP باستخدام ID Broker (HIB)
لتشغيل مهمة خلية، يمكنك اتباع الخطوات العادية لإرسال الوظيفة إلى مجموعة HDInsight ESP باستخدام ID Broker (HIB). راجع إرسال استعلامات Hive التفاعلية ونصوص دُفعات Hive لمزيد من الإرشادات.
لتشغيل مهمة PySpark تفاعلية، يمكنك اتباع الخطوات العادية لإرسال الوظيفة إلى مجموعة HDInsight ESP باستخدام ID Broker (HIB). عد إلى إرسال استعلامات PySpark التفاعلية.
لتشغيل وظيفة مجموعة PySpark، يمكنك اتباع الخطوات العادية لإرسال الوظيفة إلى مجموعة HDInsight ESP باستخدام ID Broker (HIB). راجع إرسال مهمة PySpark المجمعة للحصول على مزيد من الإرشادات.
تكوين Apache Livy
تكوين Apache Livy مدعوم. يمكنك تكوينه في ملف .VSCode \ settings.json في مجلد مساحة العمل. حالياً، لا يدعم تكوين Livy سوى نصوص Python. لمزيد من المعلومات، راجع Livy README.
أسلوب 1
- من شريط القائمة، انتقل إلى ملف > التفضيلات > الإعدادات.
- في مربع إعدادات البحث، أدخل تقديم مهمة HDInsight: Livy Conf.
- حدد Edit in settings.json لنتائج البحث ذات الصلة.
أسلوب 2
قم بإرسال ملف ولاحظ أن المجلد .vscode يضاف تلقائياً إلى مجلد العمل. يمكنك مشاهدة تكوين Livy عن طريق تحديد .vscode\settings.json.
إعدادات المشروع:

إشعار
بالنسبة إلى إعدادات driverMemory وExperMemory، قم بتعيين القيمة والوحدة. على سبيل المثال: 1جم أو 1024م.
تكوينات Livy المدعومة:
نشر /دفعات
نص الطلب
الاسم الوصف النوع ملف ملف يحتوي على التطبيق المراد تنفيذه المسار (مطلوب) proxyUser المستخدم لانتحال صفته عند تشغيل الوظيفة السلسلة className تطبيق Java/Spark فئة رئيسية السلسلة args وسيطات خط الأوامر للتطبيق قائمة سلسلة الجرار الجرار الذي سيستخدم في هذه الجلسة قائمة سلسلة ملفات pyFiles ملفات Python لاستخدامها في هذه الجلسة قائمة سلسلة الملفات الملفات التي سيتم استخدامها في هذه الجلسة قائمة سلسلة ناقل الذاكرة مقدار الذاكرة لاستخدامها في عملية النقل السلسلة برنامج تشغيل الجهاز عدد النوى المستخدمة في عملية التشغيل Int منفذ الذاكرة مقدار الذاكرة المراد استخدامها لكل عملية منفذ السلسلة المنفذ عدد النوى المراد استخدامها لكل منفذ Int عدد المنفذين عدد المنفذين الذين سيتم تشغيلهم لهذه الجلسة Int أرشيف المحفوظات التي ستستخدم في هذه الجلسة قائمة سلسلة صف اسم قائمة انتظار YARN المطلوب إرسالها إليها السلسلة الاسم اسم هذه الجلسة السلسلة كونف خصائص تكوين الحساب خريطة المفتاح=val نص الاستجابة كائن الدُفعة الذي تم إنشاؤه.
الاسم الوصف النوع بطاقة تعريف معرف جلسة العمل: Int appId معرف التطبيق لهذه الجلسة السلسلة معلومات التطبيق معلومات مفصلة عن التطبيق خريطة المفتاح=val log خطوط السجل قائمة سلسلة state حالة الدفعة السلسلة إشعار
يتم عرض تكوين Livy المعين في جزء الإخراج عندما تقوم بإرسال البرنامج النصي.
التكامل مع Azure HDInsight من Explorer
يمكنك معاينة جدول الخلية في مجموعاتك مباشرة من خلال مستكشف Azure HDInsight:
الاتصال بحسابك Azure إذا لم تكن قد فعلت ذلك بعد.
حدد رمز Azure من العمود الموجود في أقصى اليسار.
من الجزء الأيسر، قم بتوسيع AZURE: HDINSIGHT. يتم سرد الاشتراكات والمجموعات المتوفرة.
قم بتوسيع نظام المجموعة لعرض قاعدة بيانات تعريف الخلية ومخطط الجدول.
انقر بزر الماوس الأيمن فوق جدول الخلية. على سبيل المثال: hivesampletable. حدد معاينة.

تفتح نافذة Preview Results:

لوحة النتائج
يمكنك حفظ النتيجة بأكملها كملف CSV أو JSON أو Excel في مسار محلي، أو فقط حدد عدة أسطر.
لوحة الرسائل
عندما يكون عدد الصفوف في الجدول أكبر من 100، سترى الرسالة التالية: "يتم عرض أول 100 صف لجدول الخلية."
عندما يكون عدد الصفوف في الجدول أقل من 100 أو يساوي 100، سترى الرسالة التالية: "يتم عرض 60 صفاً لجدول الخلية."
عندما لا يكون هناك محتوى في الجدول، ترى الرسالة التالية: "
0 rows are displayed for Hive table."إشعار
في Linux، قم بتثبيت xclip لتمكين بيانات جدول النسخ.

الميزات الإضافية
Spark & خلية لرمز Visual Studio يدعم أيضا الميزات التالية:
IntelliSense الإكمال التلقائي. تظهر الاقتراحات للكلمات الرئيسية والأساليب والمتغيرات وعناصر البرمجة الأخرى. تمثل الرموز المختلفة أنواعاً مختلفة من الكائنات:

علامة خطأ IntelliSense. تحدد خدمة اللغة أخطاء التحرير في البرنامج النصي للخلية.
تمييز البنية. تستخدم خدمة اللغة ألواناً مختلفة للتمييز بين المتغيرات والكلمات الرئيسية ونوع البيانات والوظائف وعناصر البرمجة الأخرى:

دور القارئ فقط
لا يمكن للمستخدمين الذين تم تعيين دور القارئ فقط للمجموعة إرسال المهام إلى مجموعة HDInsight، ولا يمكنهم عرض قاعدة بيانات Hive. اتصل بمسؤول المجموعة لترقية دورك إلى HDInsight Cluster Operator في مدخل Azure. إذا كان لديك بيانات اعتماد Ambari صالحة، يمكنك ربط الكتلة يدوياً باستخدام الإرشادات التالية.
تصفح مجموعة HDInsight
عند تحديد Azure HDInsight explorer لتوسيع مجموعة HDInsight، ستتم مطالبتك بربط المجموعة إذا كان لديك دور القارئ فقط للمجموعة. استخدم الطريقة التالية للارتباط بالمجموعة باستخدام بيانات اعتماد Ambari الخاصة بك.
قم بإرسال المهمة إلى مجموعة HDInsight
عند إرسال مهمة إلى مجموعة HDInsight، ستتم مطالبتك بربط المجموعة إذا كنت في دور القارئ فقط للمجموعة. استخدم الخطوات التالية للارتباط بالمجموعة باستخدام بيانات اعتماد Ambari.
ارتباط نظام المجموعة
أدخل اسم مستخدم Ambari صالحاً.
أدخل كلمة مرور صالحة.


إشعار
يمكنك استخدام
Spark / Hive: List Clusterللتحقق من المجموعة المرتبطة:
Azure Data Lake Storage Gen2
تصفح حساب Data Lake Storage Gen2
حدد Azure HDInsight explorer لتوسيع حساب Data Lake Storage Gen2. يُطلب منك إدخال مفتاح الوصول إلى التخزين إذا كان حساب Azure الخاص بك لا يمتلك حق الوصول إلى مساحة تخزين Gen2. بعد التحقق من صحة مفتاح الوصول، يتم توسيع حساب Data Lake Storage Gen2 تلقائياً.
أرسل المهام إلى مجموعة HDInsight باستخدام Data Lake Storage Gen2
قم بإرسال وظيفة إلى مجموعة HDInsight باستخدام Data Lake Storage Gen2. تتم مطالبتك بإدخال مفتاح الوصول إلى التخزين إذا لم يكن لدى حساب Azure حق الوصول للكتابة إلى مساحة تخزين Gen2. بعد التحقق من صحة مفتاح الوصول، سيتم إرسال الوظيفة بنجاح.

إشعار
يمكنك الحصول على مفتاح الوصول لحساب التخزين من مدخل Microsoft Azure. لمزيد من المعلومات، راجع إدارة مفاتيح الوصول إلى حساب التخزين.
فك ارتباط نظام المجموعة
من شريط القائمة، انتقل إلى عرض > لوحة الأوامر ، ثم أدخل Spark / Hive: Unlink a Cluster .
حدد نظام المجموعة لإلغاء ربطها.
راجع عرض الإخراج للتحقق.
تسجيل الخروج
من شريط القائمة، انتقل إلى عرض > لوحة الأوامر ، ثم أدخل Azure: تسجيل الخروج.
المشكلات المعروفة
خطأ في تثبيت Synapse PySpark.
بالنسبة لخطأ تثبيت Synapse PySpark، نظرًا لأنه لن يتم الاحتفاظ بتبعيته بعد الآن من قبل فريق آخر، فلن يتم الاحتفاظ به بعد الآن. إذا حاولت استخدام Synapse Pyspark التفاعلي، فالرجاء استخدام Azure Synapse Analytics بدلا من ذلك. وهو تغيير على المدى الطويل.

الخطوات التالية
للحصول على فيديو يوضح استخدام Hive وSpark لتعليمة Visual Studio البرمجية، راجع Spark وHive للحصول على تعليمة Visual Studio البرمجية.